Model Seçim Eğitseli¶
Bu eğitselde, çeşitli Scikit-Learn modellerinin skorlarına bakacağız ve bunları Yellowbrick görsel tanı araçlarını kullanarak sırayla verilerimize göre en iyi modelin seçimi için karşılaştıracağız.
Model Seçim Üçlüsü¶
Makine öğrenimi tartışmaları sık sık model seçimi üzerine tekil odaklanma ile karakterize edilir. Gerek lojistik regresyon, karar ağaçları, Bayesian methodları veya yapay sinir ağları olsun; makine öğrenmesi uygulayıcıları tercihlerini genellikle hızlı bir şekilde açıklarlar. Bunun nedeni çoğunlukla tarihseldir. Modern üçüncü parti makine öğrenimi kütüphaneleri birçok modelin yayılmasını önemsiz olarak gösterse de, geleneksel olarak bu algoritmalardan birinin bile uygulaması ve ayarlanması yıllar süren çalışma gerektirmiştir. Sonuç olarak makine öğrenmesi uygulayıcıları diğerlerine göre daha belirgin (ve muhtemelen daha yaygın olan) algoritmaları daha çok tercih etmeye yönelmiştir.
Bununla birlikte, model seçimi basit şekilde “doğru” ya da “yanlış” algoritmayı seçmekten biraz daha nüanslıdır. Pratik olarak iş akışı şunları içermektedir:
- en küçük ve en kestirici tahmin kümesi seçimi ya da oluşturumu
- bir dizi algoritmaların bir model ailesinden seçimi ve
- performans optimizesi için algoritma hiperparametlerinin ayarlanması
Kumar et al tarafından model seçim üçlüsü 2015 yılı SIGMOD makalesinde ilk defa tanımlanmıştır. Makale içerisinde, tahmin edici modelleme öngörüsü için inşaa edilen yeni nesil veritabanı sistemlerinin gelişimiyle ilgili olarak, makale yazarları pratikte makine öğreniminin büyük ölçüde deneysel yapısı sebebiyle bu tür sistemlere çok fazla ihtiyaç olduğunu ifade ederler. “Model seçimini,” şu şekilde açıklarlar, “tekrarlayıcı ve keşifseldir çünkü [model seçim üçlüsü] alanı genellikle sonsuzdur ve analizçiler için yeterli doğruluk ve kavrayış sağlayabilecek bir olası [kombinasyon] bilmek genelde imkansızdır.”
Son dönemlerde makine öğrenimi iş akışının büyük bir kısmı; grid search yöntemi, standartlaştırılmıs API ler ve GUI tabanlı uygulamalar yoluyla otomatize edilmiştir. Bununla birlikte, pratikte insan sezgisi ve rehberliği, kaliteli modeller üzerinde detaylı arama yöntemlerine göre daha efektif odaklanma sağlamaktadir. Görsel model seçim işlemi yoluyla, veri bilimcileri; hatalara ve yanılgılara düşmeden finale, açıklanabilir modellere doğru ilerleyiş gösterebilmektedir.
Yellowbrick kütüphanesi, makine öğrenimi için veri bilimcilerine model seçim sürecine yön vermelerine olanak sağlayan bir tanı görselleştirme platformudur. Yellowbrick, Scikit Learn API`sini yeni bir temel obje ile genişletmiştir: Görselleştirici. Görselleştiriciler, çok boyutlu verilerin dönüşümü sırasında görsel tanılar sunarak, Scikit-Learn işlem sürecinin bir parçası olarak görsel modellerin uymasını ve dönüşümünü sağlamaktadır.
Veri Hakkında¶
Bu eğitselde UCI Machine Learning Repository adresinden alınan mantar veriseti nin düzenlenmiş versiyonu kullanılmaktadır. Amacımız, bir mantarın karakteristik özelliklerine göre zehirli ya da yenilebilir olup olmadığını tahmin etmektir.
Veri, Agaricus ve Lepiota ailesine ait 23 çeşit solungaçlı mantar türüyle ilgili varsayımsal örneklerin açıklamalarını içermektedir. Her tür, kesinlikle yenilebilir kesinlikle yenemez veya yenilebilirliği bilinmeyen ya da tavsiye edilmeyen olarak tanımlanmıştır. (bu son sınıf zehirli sınıfı ile birleştirilmiştir).
Dosyamız, “agaricus-lepiota.txt,” 3 nominal değerli öznitelikleri ve 8124 mantar örneğinin hedef değerlerini içermektedir. (4208 yenilebilir, 3916 zehirli).
Haydi Pandas ile verimizi yükleyelim.
import os
import pandas as pd
names = [
'class',
'cap-shape',
'cap-surface',
'cap-color'
]
mushrooms = os.path.join('data','agaricus-lepiota.txt')
dataset = pd.read_csv(mushrooms)
dataset.columns = names
dataset.head()
| . | class | cap-shape | cap-surface | cap-color |
|---|---|---|---|---|
| 0 | edible | bell | smooth | white |
| 1 | poisonous | convex | scaly | white |
| 2 | edible | convex | smooth | gray |
| 3 | edible | convex | scaly | yellow |
| 4 | edible | bell | smooth | white |
features = ['cap-shape', 'cap-surface', 'cap-color']
target = ['class']
X = dataset[features]
y = dataset[target]
Özellik Çıkarımı¶
Verimiz, hedef de dahil olmak üzere kategoriktir. Makine öğrenmesi için bu değerleri sayısal değerlere çevirmemiz gerekecek. Sırasıyla veri setimizden bunu sağlamak amacıyla, veri setinde bulunan değerleri bir modele uygun birşeylere dönüştürmemiz için Scikit-Learn dönüştürücülerini kullanmamız gerekmektedir. Neyseki Scikit-Learn, kategorik etiketleri sayısal integer değerlerine çevirecek dönüştürücü sağlamaktadır sklearn.preprocessing.LabelEncoder. Maalesef tek seferde sadece bir vektörü dönüştürebiliriz, bu yüzden birden fazla sütuna sırayla uygulamamız için uyarlama yapmamız gerekiyor.
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
class EncodeCategorical(BaseEstimator, TransformerMixin):
"""
Encodes a specified list of columns or all columns if None.
"""
def __init__(self, columns=None):
self.columns = [col for col in columns]
self.encoders = None
def fit(self, data, target=None):
"""
Expects a data frame with named columns to encode.
"""
# Encode all columns if columns is None
if self.columns is None:
self.columns = data.columns
# Fit a label encoder for each column in the data frame
self.encoders = {
column: LabelEncoder().fit(data[column])
for column in self.columns
}
return self
def transform(self, data):
"""
Uses the encoders to transform a data frame.
"""
output = data.copy()
for column, encoder in self.encoders.items():
output[column] = encoder.transform(data[column])
return output
Modelleme ve Değerlendirme¶
Sınıflandırıcı Değerlendirmesi için Genel Metrikler¶
Precision gerçek olan pozitif sonuçların toplam sayısının, tüm pozitif çıkan sonuçların sayısına bölünmesidir. (ör. Yenilebilir olarak tahmin ettiğimiz mantarların aslinda ne kadarı gerçekten yenilebilir).
Recall gerçek olan pozitif sonuçların toplam sayısının, tüm pozitif çıkması gereken sonuçların sayısına bölünmesidir. (ör. Zehirli mantarların ne kadarını kesin zehirli olarak tahmin edebildik).
F1 score bir testin doğruluğunun ölçüsüdür. Bu skoru hesaplamak için testin hem kesinlik hem de hassasiyeti dikkate alınmaktadır. F1 skoru; en iyi değer 1 ve en kötü değer 0’a ulaştğı yerde, kesinlik ve hassasiyetin ağırlıklı ortalaması olarak da yorumlanabilir.
kesinlik = gerçek pozitifler / (gerçek pozitifler + yanlış pozitifler)
hassasiyet = gerçek pozitifler / (yanlış negatifler + gerçek pozitifler)
F1 skoru = 2 * ((kesinlik * hassasiyet) / (kesinlik + hassasiyet))
precision = true positives / (true positives + false positives)
recall = true positives / (false negatives + true positives)
F1 score = 2 * ((precision * recall) / (precision + recall))
Şimdi bazı tahminleri yapabilmek için hazırız.
Birden fazla tahmin edicilerin değerlendirilmesi için bir yol oluşturalım – Öncelikle klasik sayısal skorları (daha sonra Yellowbrick kütüphanesinden bazı görsel tanı araçlarıyla karşılaştırma yapacağımız) kullanarak.
from sklearn.metrics import f1_score
from sklearn.pipeline import Pipeline
def model_selection(X, y, estimator):
"""
Test various estimators.
"""
y = LabelEncoder().fit_transform(y.values.ravel())
model = Pipeline([
('label_encoding', EncodeCategorical(X.keys())),
('one_hot_encoder', OneHotEncoder()),
('estimator', estimator)
])
# Instantiate the classification model and visualizer
model.fit(X, y)
expected = y
predicted = model.predict(X)
# Compute and return the F1 score (the harmonic mean of precision and recall)
return (f1_score(expected, predicted))
# Try them all!
from sklearn.svm import LinearSVC, NuSVC, SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegressionCV, LogisticRegression, SGDClassifier
from sklearn.ensemble import BaggingClassifier, ExtraTreesClassifier, RandomForestClassifier
model_selection(X, y, LinearSVC())
0.65846308387744845
model_selection(X, y, NuSVC())
0.63838842388991346
model_selection(X, y, SVC())
0.66251459711950167
model_selection(X, y, SGDClassifier())
0.69944182052382997
model_selection(X, y, KNeighborsClassifier())
0.65802139037433149
model_selection(X, y, LogisticRegressionCV())
0.65846308387744845
model_selection(X, y, LogisticRegression())
0.65812609897010799
model_selection(X, y, BaggingClassifier())
0.687643484132343
model_selection(X, y, ExtraTreesClassifier())
0.68713648045448383
model_selection(X, y, RandomForestClassifier())
0.69317131158367451
İlk Model Değerlendirmesi¶
Yukarıdaki F1 skorlarının sonuçlarını baz aldığınızda hangi model en iyi performansı göstermiştir?
Görsel Model Değerlendirmesi¶
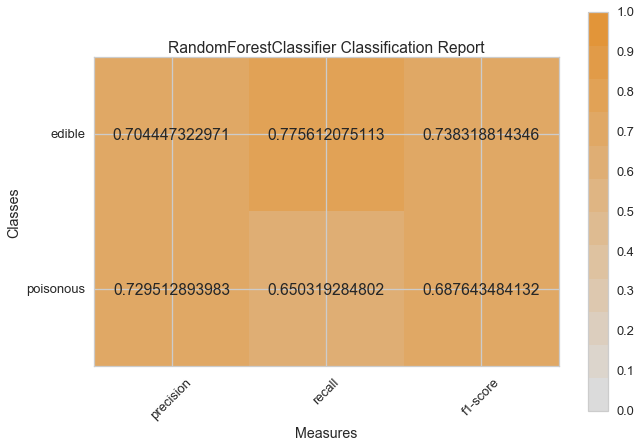
Haydi şimdi model değerlendirme fonksiyonumuzu, Yellowbrick ClassificationReport sınıfını kullanmak için tekrar düzenleyelim, bir model görselleştiricisi; kesinlik, hassasiyet ve F1 skorlarını göstermektedir. Bu görsel model analiz aracı renk kodlu ısı haritasında olduğu gibi sayısal skorları, kolay yorumlama ve saptamaya destek amacıyla; özellikle kullanım durumumuzdaki amaca uygun (hayat kurtarıcı, dengeli) Tip I ve Tip II hata nüanslarını birleştirir.
Tip I hata (veya “yanlış pozitif”) mevcut olmayan bir etkiyi tespit eder. (ör. aslında yenilebilir bir mantarın zehirli olarak saptanması).
Tip II hata (veya “yanlış negatif”) mevcut olan bir etkiyi tespit edememektir. (ör. aslında zehirli bir mantarın yenilebilir olduğuna inanılması).
from sklearn.pipeline import Pipeline
from yellowbrick.classifier import ClassificationReport
def visual_model_selection(X, y, estimator):
"""
Test various estimators.
"""
y = LabelEncoder().fit_transform(y.values.ravel())
model = Pipeline([
('label_encoding', EncodeCategorical(X.keys())),
('one_hot_encoder', OneHotEncoder()),
('estimator', estimator)
])
# Instantiate the classification model and visualizer
visualizer = ClassificationReport(model, classes=['edible', 'poisonous'])
visualizer.fit(X, y)
visualizer.score(X, y)
visualizer.poof()
visual_model_selection(X, y, LinearSVC())
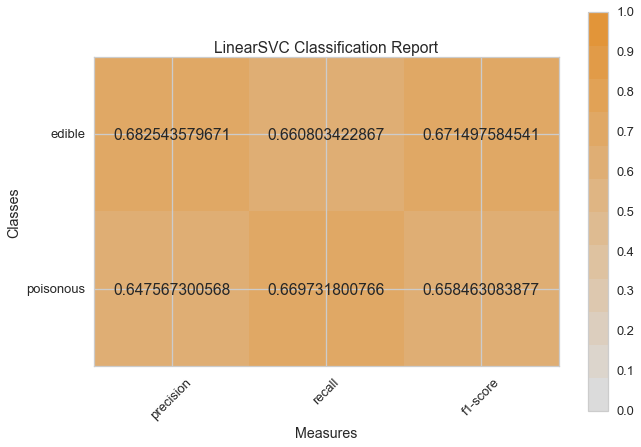
visual_model_selection(X, y, NuSVC())
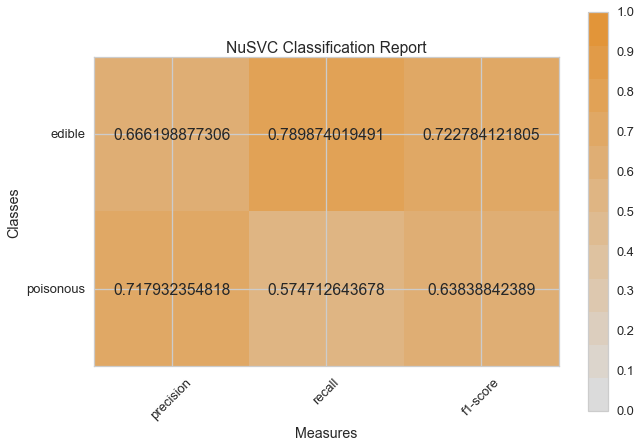
visual_model_selection(X, y, SVC())
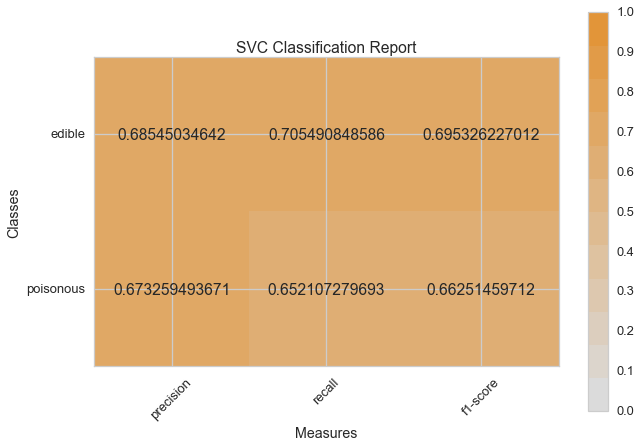
visual_model_selection(X, y, SGDClassifier())
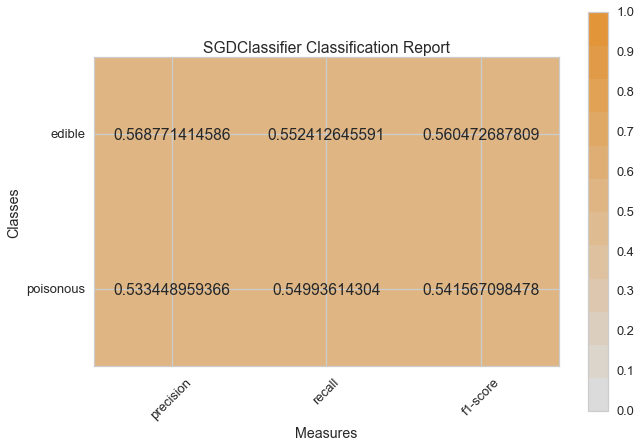
visual_model_selection(X, y, KNeighborsClassifier())
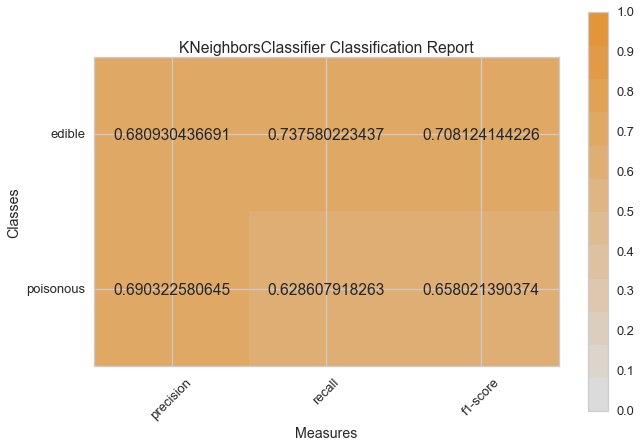
visual_model_selection(X, y, LogisticRegressionCV())
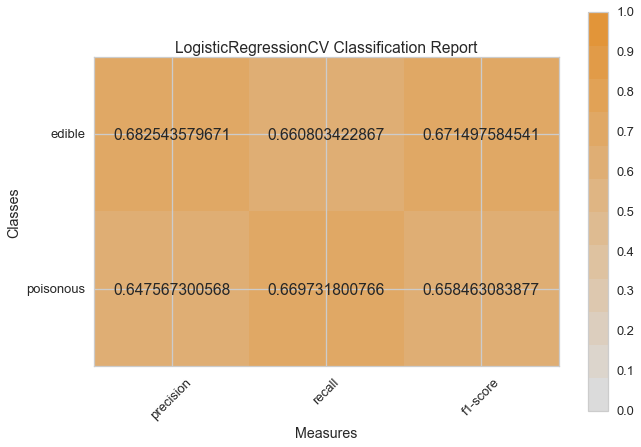
visual_model_selection(X, y, LogisticRegression())
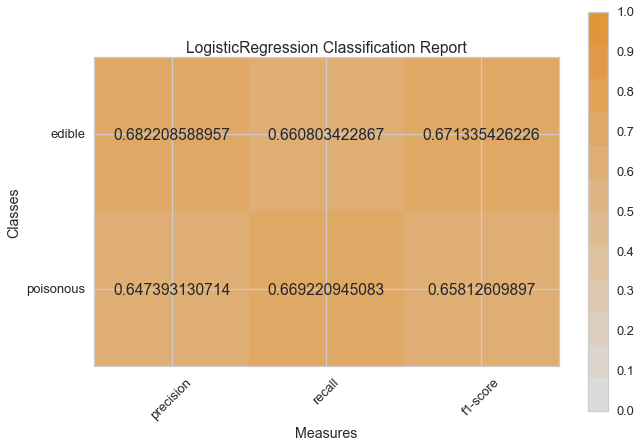
visual_model_selection(X, y, BaggingClassifier())
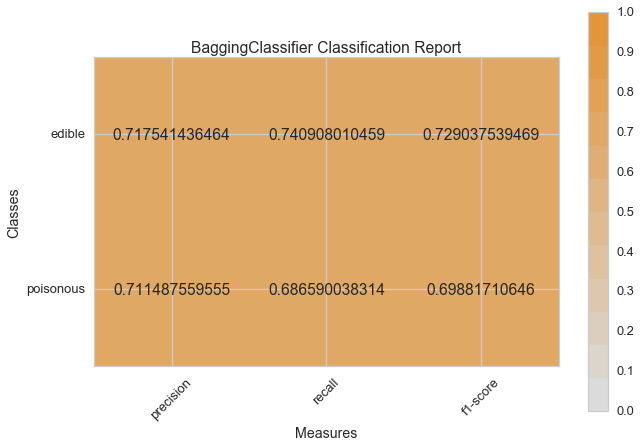
visual_model_selection(X, y, ExtraTreesClassifier())
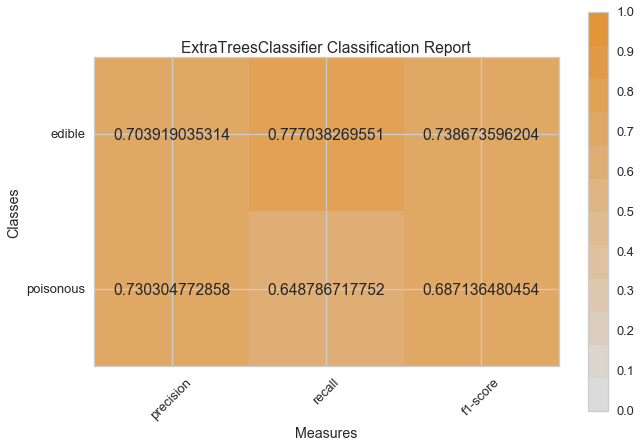
visual_model_selection(X, y, RandomForestClassifier())
Değerlendirme¶
- Hangi model en iyi gözükmektedir? Niçin?
- Hangisi büyük ihtimalle hayatınızı kurtaracaktır?
- Görsel model değerlendirme deneyiminin, sayısal model değerlendirmesinden farkı nedir?