Inicio rápido
Si eres nuevo en Yellowbrick, esta guía te ayudará a incluir visualizadores en tu flujo de trabajo de machine learning. Sin embargo, antes de comenzar, hay varias notas sobre entornos de desarrollo que debes considerar.
Yellowbrick tiene dos dependencias primarias: scikit-learn y matplotlib. Si no tiene estos paquetes de Python, se instalarán junto con Yellowbrick. Tenen cuenta que Yellowbrick funciona mejor con scikit-learn version 0.20 o posterior y matplotlib versión 3.0.1 o posterior. Ambos paquetes requieren que se compile algún código C, lo que puede ser difícil en algunos sistemas, como Windows. Si tiene problemas, intente usar una distribución de Python que incluya estos paquetes como Anaconda.
Yellowbrick también se usa comúnmente dentro de un Jupyter Notebook junto con marcos de datos Pandas. Los blocs de notas hacen que sea especialmente fácil coordinar el código y las visualizaciones; sin embargo, también puedes usar Yellowbrick dentro de los scripts normales de Python, ya sea guardando figuras en el disco o mostrando figuras en una ventana de GUI. Si tienes problemas con esto, consulte la documentación de backends de matplotlib.
Nota
Jupyter, Pandas y otras bibliotecas auxiliares como Natural Language Toolkit (NLTK) para visualizadores de texto no se instalan con Yellowbrick y deben instalarse por separado.
Instalación
Yellowbrick es un paquete de Python 3 y funciona bien con 3.4 o posterior. La forma más sencilla de instalar Yellowbrick es desde PyPI con pip, el instalador de paquetes preferido de Python.
$ pip install yellowbrick
Ten en cuenta que Yellowbrick es un proyecto activo y publica rutinariamente nuevas versiones con más visualizadores y actualizaciones. Para actualizar Yellowbrick a la última versión, use pip de la siguiente manera.
$ pip install -U yellowbrick
También puede usar la marca -U para actualizar scikit-learn, matplotlib o cualquier otra utilidad de terceros que funcione bien con Yellowbrick a sus últimas versiones.
Si estás utilizando Anaconda, puede aprovechar la utilidad conda para instalar el paquete Anaconda Yellowbrick package:
conda install -c districtdatalabs yellowbrick
Si tienes problemas con la instalación, comunícanoslo en GitHub.
Una vez instalado, debería poder importar Yellowbrick sin error, tanto en Python como dentro de las notas de Jupyter. Ten en cuenta que debido a matplotlib, Yellowbrick no funciona dentro de un entorno virtual en macOS sin saltar a través de algunos aros.
Uso de Yellowbrick
La API de Yellowbrick está diseñada específicamente para jugar muy bien con scikit-learn. La interfaz principal es, por lo tanto, un Visualizer – un objeto que aprende de los datos para producir una visualización. Los visualizadores son objetos scikit-learn Estimator y tienen una interfaz similar junto con métodos para dibujar. Para usar visualizadores, simplemente use el mismo flujo de trabajo que con un modelo scikit-learn, inserte el visualizador, cree una instancia, llame al método fit(), luego para renderizar la visualización, llame al método show() del visualizador.
Por ejemplo, hay varios visualizadores que actúan como transformadores, utilizados para realizar un análisis antes de instalar un modelo. En el ejemplo siguiente se visualiza un conjunto de datos de alta dimensión con coordenadas paralelas:
from yellowbrick.features import ParallelCoordinates
visualizer = ParallelCoordinates()
visualizer.fit_transform(X, y)
visualizer.show()
Como puedes ver, el flujo de trabajo es muy similar al uso de un transformador scikit-learn, y los visualizadores están destinados a integrarse junto con las utilidades scikit-learn. Los argumentos que cambian la forma en que se dibuja la visualización se pueden pasar al visualizador en la creación de instancias, de manera similar a cómo se incluyen los hiperparámetros con los modelos scikit-learn.
El método show() finaliza el dibujo (agregando títulos, etiquetas de ejes, etc.) y luego representa la imagen. Si estás en un cuaderno Jupyter, la imagen debería simplemente aparecer escrita en la salida del notebook. Si está en un script de Python, debería abrirse una ventana de GUI con la visualización en forma interactiva. Sin embargo, también puede guardar la imagen en el disco pasando una ruta de archivo de la siguiente manera:
visualizer.show(outpath="pcoords.png")
La extensión del nombre de archivo determinará cómo se representa la imagen. Además del .png, .pdf también se usa comúnmente para imágenes listas para publicación de alta calidad.
Nota
La entrada de datos a Yellowbrick es idéntica a la de scikit-learn. Los conjuntos de datos son generalmente se describe con una variable X (a veces denominada simplemente como datos) y una variable opcional y (generalmente referida como el objetivo). Los datos requeridos X son una tabla que contiene instancias (o muestras) que se describen por características. X es, por lo tanto, una matriz bidimensional con una forma de (n, m) donde n es el número de instancias (filas) y m es el número de entidades (columnas). X puede ser un Pandas DataFrame, una matriz NumPy o incluso una lista de listas de Python.
Los datos de destino opcionales, y, se utilizan para especificar la verdad básica en el machine learning supervisado. y es un vector (una matriz unidimensional) que debe tener longitud n – el mismo número de elementos que filas en X. y puede ser una serie de Pandas, una matriz Numpy o una lista de Python.
Los visualizadores también pueden envolver modelos scikit-learn para evaluación, ajuste de hiperparámetros y selección de algoritmos. Por ejemplo, para producir un mapa de calor visual de un informe de clasificación, que muestre la precisión, el recall, la puntuación F1 y el soporte para cada clase en un clasificador, envuelva el estimador en un visualizador de la siguiente manera:
from yellowbrick.classifier import ClassificationReport
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
visualizer = ClassificationReport(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
Solo se requieren dos líneas de código adicionales para agregar una evaluación visual del modelo clasificador, la creación de instancias de un visualizador ClassificationReport que envuelve el estimador de clasificación y una llamada a su método show(). De esta manera, el visualizador mejora el flujo de trabajo de machine learning sin interrumpirlo.
La API basada en clases está destinada a integrarse con scikit-learn directamente, sin embargo, en ocasiones hay momentos en que solo necesita una visualización rápida. Yellowbrick admite funciones rápidas para aprovechar esto directamente. Por ejemplo, los dos diagnósticos visuales podrían haberse implementado de la siguiente manera:
from sklearn.linear_model import LogisticRegression
from yellowbrick.features import parallel_coordinates
from yellowbrick.classifier import classification_report
# Displays parallel coordinates
g = parallel_coordinates(X, y)
# Displays classification report
g = classification_report(LogisticRegression(), X, y)
Estas funciones rápidas le brindan un poco menos de control sobre el flujo de trabajo de machine learning, pero rápidamente le brindan diagnósticos a pedido y son muy útiles para procesos exploratorios.
Tutorial
Consideremos un análisis de regresión como un ejemplo simple del uso de visualizadores en el flujo de trabajo de machine learning. Utilizando un conjunto de datos de bicicletas compartidas basado en el cargado en el UCI Machine Learning Repository, nos gustaría predecir el número de bicicletas alquiladas en una hora determinada en función de características como la temporada, el clima o si es un día festivo.
Nota
Hemos actualizado el conjunto de datos desde el repositorio UCI ML para que sea un poco más fácil de cargar en Pandas; asegúrese de descargar la versión Yellowbrick del conjunto de datos utilizando el método load_bikeshare a continuación. Ten en cuenta también que Pandas debe seguir el código suministrado. Los Pandas se pueden instalar usando pip install pandas si aún no lo has instalado.
Podemos cargar nuestros datos utilizando el módulo yellowbrick.datasets de la siguiente manera:
import pandas as pd
from yellowbrick.datasets import load_bikeshare
X, y = load_bikeshare()
print(X.head())
Esto imprime las primeras líneas de nuestro conjunto de datos que se ve como:
season year month hour holiday weekday workingday weather temp \
0 1 0 1 0 0 6 0 1 0.24
1 1 0 1 1 0 6 0 1 0.22
2 1 0 1 2 0 6 0 1 0.22
3 1 0 1 3 0 6 0 1 0.24
4 1 0 1 4 0 6 0 1 0.24
feelslike humidity windspeed
0 0.2879 0.81 0.0
1 0.2727 0.80 0.0
2 0.2727 0.80 0.0
3 0.2879 0.75 0.0
4 0.2879 0.75 0.0
El flujo de trabajo de machine learning es el arte de crear triples de selección de modelos, una combinación de características, algoritmos e hiperparámetros que identifica de forma única en un modelo ajustado a un conjunto de datos específico. Como parte de nuestra selección de características, queremos identificar características que tienen una relación lineal entre sí, lo que potencialmente introduce covarianza en nuestro modelo y rompe el OLS (guiándonos hacia la eliminación de características o el uso de la regularización). Podemos usar el visualizador Rank Features para calcular las correlaciones de Pearson entre todos los pares de características de la siguiente manera:
from yellowbrick.features import Rank2D
visualizer = Rank2D(algorithm="pearson")
visualizer.fit_transform(X)
visualizer.show()
(Source code, png, pdf)
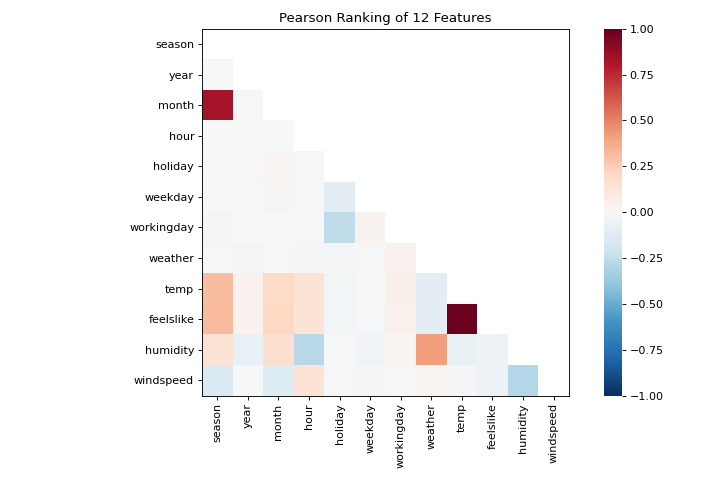{kind=link}
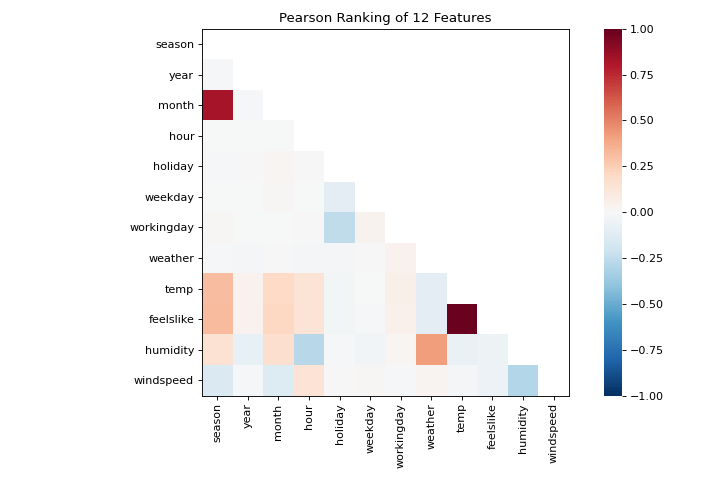
Esta figura nos muestra la correlación de Pearson entre pares de características tales que cada celda de la cuadrícula representa dos características identificadas en orden en los ejes x e y cuyo color muestra la magnitud de la correlación. Una correlación de Pearson de 1.0 significa que hay una fuerte relación positiva y lineal entre los pares de variables y un valor de -1.0 indica una fuerte relación lineal (un valor de cero indica que no hay relación). Por lo tanto, estamos buscando cuadros de color rojo oscuro y azul oscuro para identificar más.
En este gráfico, vemos que las características temp y feelslike tienen una fuerte correlación y también que la característica season tiene una fuerte correlación con la característica month. Esto parece tener sentido; la temperatura aparente que sentimos afuera depende de la temperatura real y otros factores de calidad del aire, ¡y la estación del año se describe por mes! Para profundizar más, podemos usar el:doc:api/features/jointplot (JointPlotVisualizer) para inspeccionar esas relaciones.
from yellowbrick.features import JointPlotVisualizer
visualizer = JointPlotVisualizer(columns=['temp', 'feelslike'])
visualizer.fit_transform(X, y)
visualizer.show()
(Source code, png, pdf)
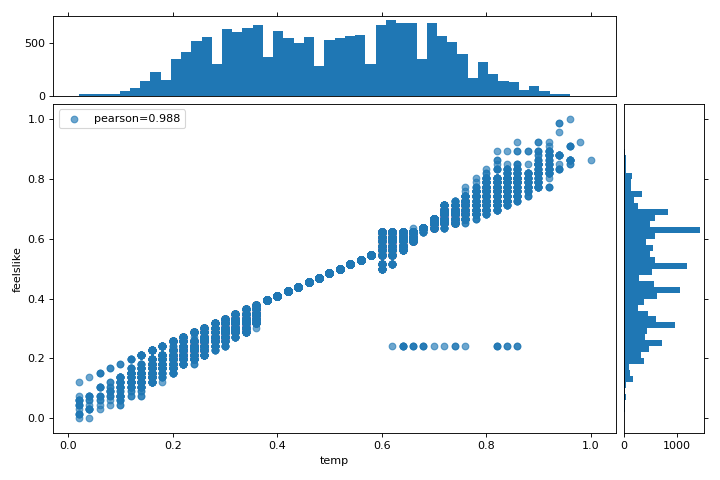{kind=link}
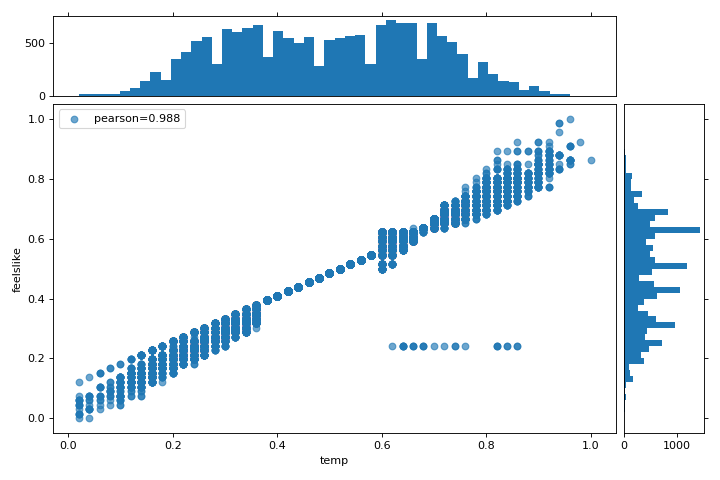
Este visualizador traza un diagrama de dispersión de la temperatura aparente en el eje y y la temperatura real medida en el eje x y dibuja una línea de mejor ajuste utilizando una regresión lineal simple. Además, las distribuciones univariadas se muestran como histogramas por encima del eje x para la temperatura y junto al eje y para``feelslike``. El JointPlotVisualizer ofrece una vista rápida de la correlación positiva muy fuerte de las características, así como el rango y la distribución de cada característica. Ten en cuenta que los ejes se normalizan al espacio entre cero y uno, una técnica común en el machine learning para reducir el impacto de una característica sobre otra.
Esta gráfica es muy interesante porque parece haber algunos valores atípicos en el conjunto de datos. Es posible que estas instancias deban eliminarse manualmente para mejorar la calidad del modelo final, ya que pueden representar errores de entrada de datos y potencialmente entrenar el modelo en un conjunto de datos sesgado que devolvería predicciones de modelo poco confiables. La primera instancia de valores atípicos ocurre en los datos temporales donde el valor feelslike es aproximadamente igual a 0.25, mostrando una línea horizontal de datos, probablemente creada por un error de entrada.
También podemos ver que las temperaturas más extremas crean un efecto exagerado en la temperatura percibida; cuanto más frío es, más frío es probable que las personas crean que es, y cuanto más cálido es, más cálido se percibe que es, con temperaturas moderadas que generalmente tienen poco efecto en la percepción individual de la comodidad. Esto nos da una pista de que feelslike puede ser una mejor característica que temp prometiendo un conjunto de datos más estable, con menos riesgo de encontrarse con valores atípicos o errores.
En última instancia, podemos confirmar la suposición entrenando nuestro modelo en cualquiera de los valores y puntuando los resultados. Si el valor temp es de hecho menos confiable, debemos eliminar la variable temp en favor de feelslike . Mientras tanto, usaremos el valor feelslike debido a la ausencia de valores atípicos y errores de entrada.
En este punto, podemos entrenar nuestro modelo; ajustemos una regresión lineal a nuestro modelo y grafiquemos los residuos.
from yellowbrick.regressor import ResidualsPlot
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1
)
visualizer = ResidualsPlot(LinearRegression())
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
(Source code, png, pdf)
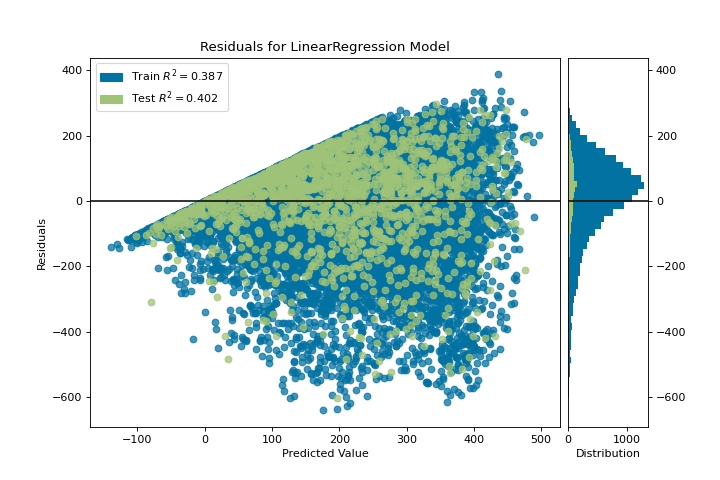{kind=link}
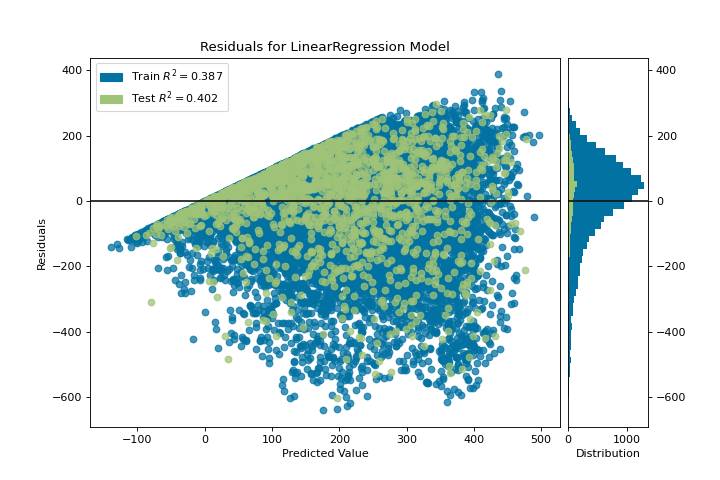
La gráfica de residuos muestra el error frente al valor predicho (el número de ciclistas), y nos permite buscar heterocedasticidad en el modelo; por ejemplo, regiones del destino donde el error es mayor. La forma de los residuos puede informarnos directamente dónde OLS (mínimos cuadrados ordinarios) está siendo más fuertemente afectado por los componentes de nuestro modelo (las características). En este caso, podemos ver que el menor número previsto de ciclistas da como resultado un menor error del modelo y, a la inversa, que el número máximo de ciclistas predicho da como resultado un mayor error del modelo. Esto indica que nuestro modelo tiene más ruido en ciertas regiones del objetivo o que dos variables son colineales, lo que significa que están inyectando error a medida que cambia el ruido en su relación.
La gráfica de residuos también muestra cómo el modelo está inyectando error, la línea horizontal en negrita en residuals = 0 no es ningún error, y cualquier punto por encima o por debajo de esa línea indica la magnitud del error. Por ejemplo, la mayoría de los residuos son negativos, y dado que la puntuación se calcula como actual - expected, esto significa que el valor esperado es mayor que el valor real la mayor parte del tiempo; por ejemplo, que nuestro modelo está adivinando principalmente más que el número real de ciclistas. Además, hay un perímetro muy interesante a lo largo de la parte superior derecha del gráfico de residuos, lo que indica un efecto interesante en el espacio del modelo; posiblemente que alguna característica esté fuertemente ponderada en la región de ese modelo.
Finalmente, los residuos son coloreados por entrenamiento y conjunto de pruebas. Esto nos ayuda a identificar errores en la creación de divisiones de entrenamiento y prueba. Si el error de prueba no coincide con el error del entrenamiento, entonces nuestro modelo está sobreajustado o subajustado. De lo contrario, podría ser un error al mezclar el conjunto de datos antes de crear las divisiones.
Junto con la generación de la gráfica de residuos, también medimos el rendimiento por «puntuación» nuestro modelo en los datos de la prueba, por ejemplo, el fragmento de código visualizer.score(X_test, y_test). Debido a que utilizamos un modelo de regresión lineal, la puntuación consiste en encontrar el R-squared de los datos, que es una medida estadística de qué tan cerca están los datos de la línea de regresión ajustada. El valor R-cuadrado de cualquier modelo puede variar ligeramente entre las ejecuciones de predicción/prueba, sin embargo, generalmente debe ser comparable. En nuestro caso, el valor R-cuadrado para este modelo fue de solo 0.328, lo que sugiere que la correlación lineal puede no ser la más adecuada para ajustar estos datos. Veamos si podemos encajar un mejor modelo usando regularización, y exploremos otro visualizador al mismo tiempo.
import numpy as np
from sklearn.linear_model import RidgeCV
from yellowbrick.regressor import AlphaSelection
alphas = np.logspace(-10, 1, 200)
visualizer = AlphaSelection(RidgeCV(alphas=alphas))
visualizer.fit(X, y)
visualizer.show()
(Source code, png, pdf)
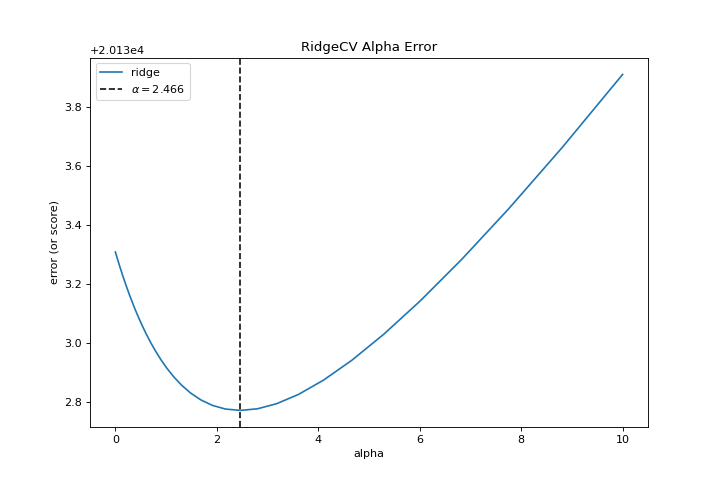{kind=link}
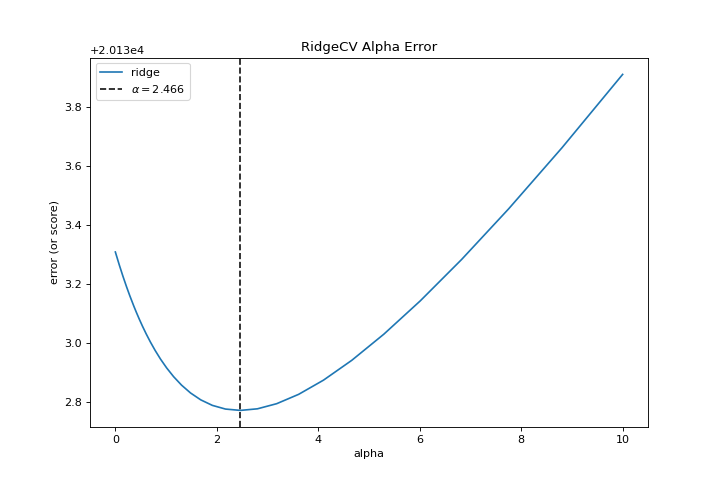
Al explorar familias modelo, lo principal a considerar es cómo el modelo se vuelve más complejo. A medida que el modelo aumenta en complejidad, el error debido a la varianza aumenta porque el modelo se está volviendo más sobreajustado y no puede generalizar a datos invisibles. Sin embargo, cuanto más simple es el modelo, más error es probable que se deba a un sesgo; el modelo está mal ajustado y, por lo tanto, pierde su objetivo con mayor frecuencia. Por lo tanto, el objetivo de la mayoría del machine learning es crear un modelo que sea lo suficientemente complejo, encontrando un término medio entre el sesgo y la varianza.
Para un modelo lineal, la complejidad proviene de las características mismas y su peso asignado de acuerdo con el modelo. Por lo tanto, los modelos lineales esperan el menor número de características que logre un resultado explicativo. Una técnica para lograr esto es la regularización, la introducción de un parámetro llamado alfa que normaliza los pesos de los coeficientes entre sí y penaliza la complejidad. Alfa y complejidad tienen una relación inversa, cuanto mayor es el alfa, menor es la complejidad del modelo y viceversa.
La pregunta es cómo elegir alfa. Una técnica es ajustar una serie de modelos utilizando la validación cruzada y seleccionando el alfa que tenga el error más bajo. El visualizador AlphaSelection te permite hacer precisamente eso, con una representación visual que muestra el comportamiento de la regularización. Como puede ver en la figura anterior, el error disminuye a medida que el valor de alfa aumenta hasta nuestro valor elegido (en este caso, 3.181) donde el error comienza a aumentar. Esto nos permite apuntar a la compensación sesgo/varianza y explorar la relación de los métodos de regularización (por ejemplo, Ridge vs. Lasso).
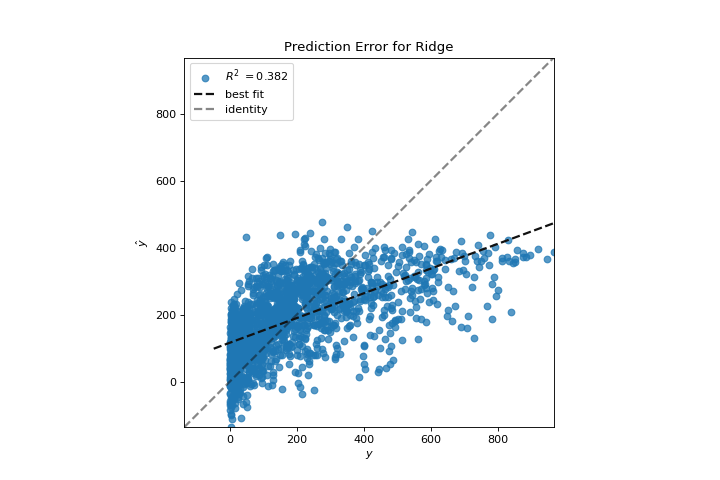
Ahora podemos entrenar nuestro modelo final y verlo con el visualizador PredictionError:
from sklearn.linear_model import Ridge
from yellowbrick.regressor import PredictionError
visualizer = PredictionError(Ridge(alpha=3.181))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
(Source code, png, pdf)
{kind=link}
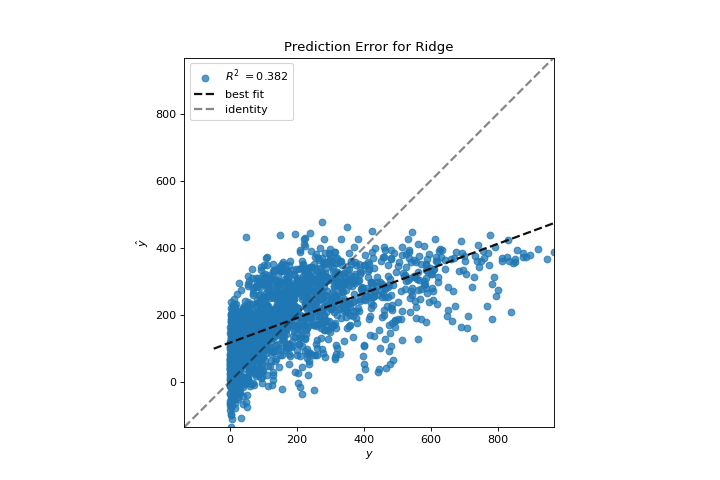
El visualizador de errores de predicción traza los valores reales (medidos) frente a los esperados (predichos) entre sí. La línea negra punteada es la línea de 45 grados que indica cero errores. Al igual que la gráfica de residuos, esto nos permite ver dónde se está produciendo el error y en qué magnitud.
En esta gráfica, podemos ver que la mayor parte de la densidad de instancias es inferior a 200 ciclistas. Es posible que deseemos probar la búsqueda de coincidencia ortogonal o splines para ajustarnos a una regresión que tenga en cuenta más regionalidad. También podemos notar que la extraña topología de la gráfica de residuos parece estar mejorar usando la regresión de Ridge, y que hay un poco más de equilibrio en nuestro modelo entre valores grandes y pequeños. Potencialmente, la regularización de Ridge curó un problema de covarianza que teníamos entre dos características. A medida que avanzamos en nuestro análisis utilizando otros modelos, podemos continuar utilizando visualizadores para comparar y ver rápidamente nuestros resultados.
¡Esperamos que este flujo de trabajo te dé una idea de cómo integrar visualizadores en el machine learning con scikit-learn y te inspire a usarlo en tu trabajo y escribir el tuyo! Para obtener información adicional sobre cómo comenzar con Yellowbrick, consulte el Tutorial de selección de modelos. Después de eso, puedes ponerte al día con visualizadores específicos detallados en Visualizers and API.