Los «Oneliners»
¡Los métodos rápidos de Yellowbrick son visualizadores de una sola línea de código!
Yellowbrick está diseñado para darte tanto control como desees sobre las gráficas que crees, ofreciendo parámetros para ayudarte a personalizar todo, desde el color, el tamaño y el título hasta la evaluación preferida o la medida de correlación, las líneas de mejor ajuste opcionales o histogramas y las técnicas de validación cruzada. Para obtener más información sobre cómo personalizar sus visualizaciones utilizando esos parámetros, consulte Visualizers and API.
Pero… ¡a veces solo quieres construir un gráfico con una sola línea de código!
En esta página exploraremos los métodos rápidos de Yellowbrick (también conocidos como «oneliners»), que devuelven un objeto visualizador completamente ajustado y listo en una sola línea.
Nota
Esta página ilustra oneliners para algunos de nuestros visualizadores más populares para análisis de características, clasificación, regresión, agrupación y evaluación de objetivos, pero no es una lista completa. ¡Casi todos los visualizadores de Yellowbrick tienen un método rápido asociado!
Análisis de características
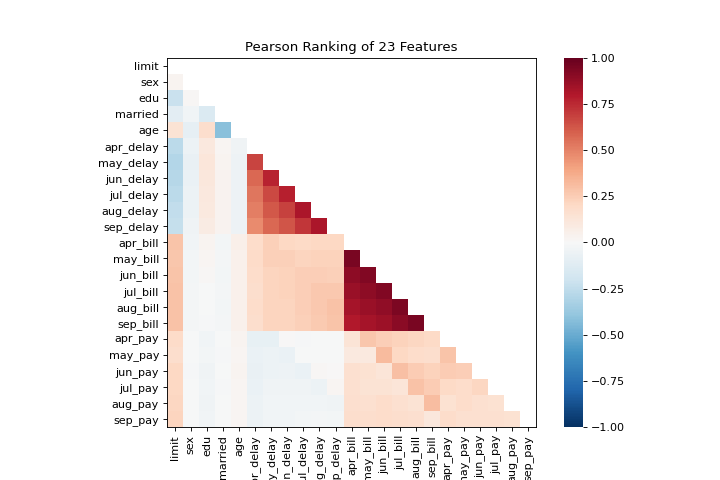
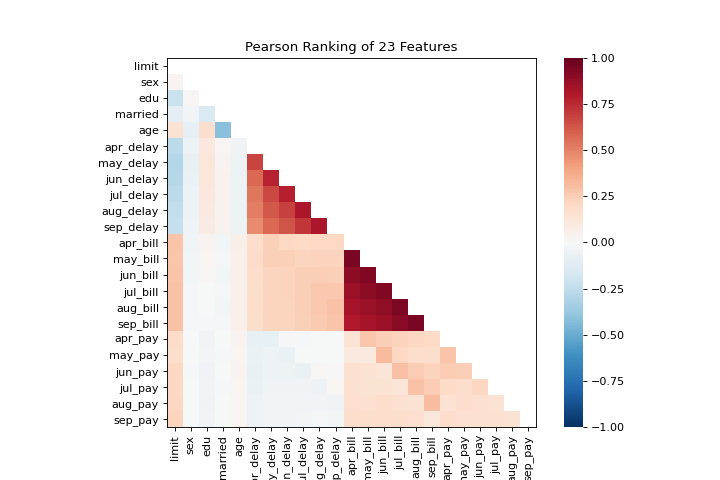
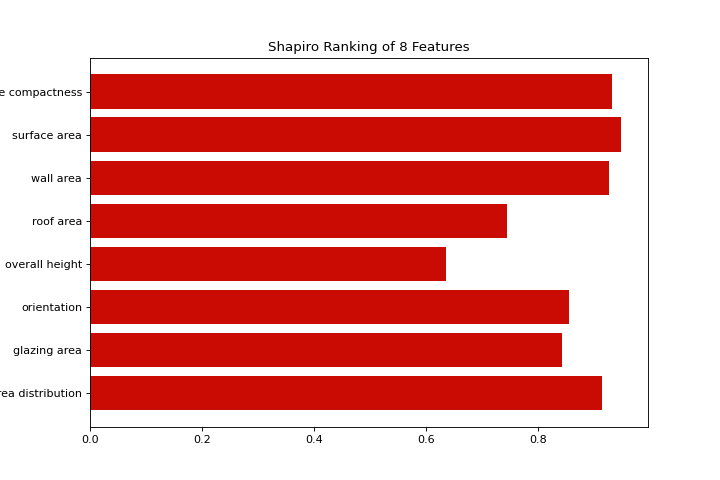
Rank2D
Los gráficos rank1d y rank2d muestran clasificaciones por pares o características para ayudarte a detectar relaciones. Conoce más en:doc:api/features/rankd.
from yellowbrick.features import rank2d
from yellowbrick.datasets import load_credit
X, _ = load_credit()
visualizer = rank2d(X)
(Source code, png, pdf)
{kind=link}
from yellowbrick.features import rank1d
from yellowbrick.datasets import load_energy
X, _ = load_energy()
visualizer = rank1d(X, color="r")
(Source code, png, pdf)
{kind=link}
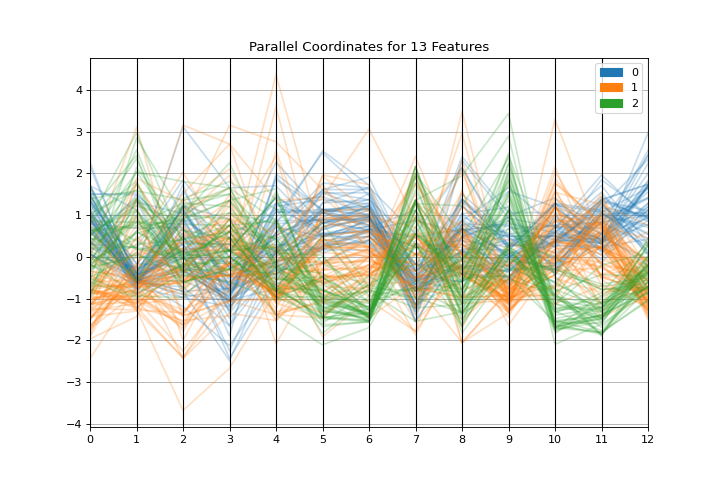
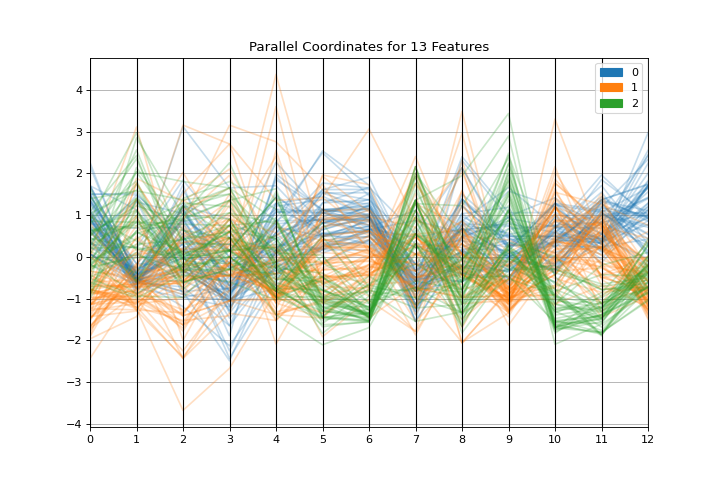
Coordenadas paralelas
La gráfica parallel_coordinates es una visualización horizontal de instancias, clasificadas por las características que las describen. Conoce más en Parallel Coordinates.
from sklearn.datasets import load_wine
from yellowbrick.features import parallel_coordinates
X, y = load_wine(return_X_y=True)
visualizer = parallel_coordinates(X, y, normalize="standard")
(Source code, png, pdf)
{kind=link}
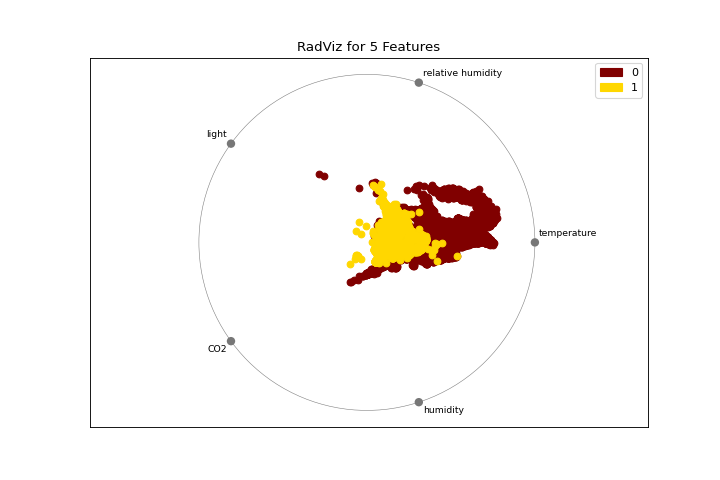
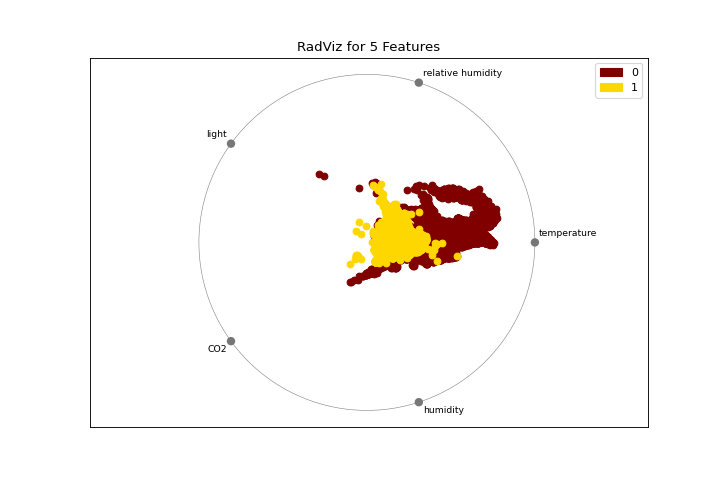
Visualización radial
La gráfica radviz muestra la separación de instancias alrededor de un círculo unitario. Conoce más en RadViz Visualizer.
from yellowbrick.features import radviz
from yellowbrick.datasets import load_occupancy
X, y = load_occupancy()
visualizer = radviz(X, y, colors=["maroon", "gold"])
(Source code, png, pdf)
{kind=link}
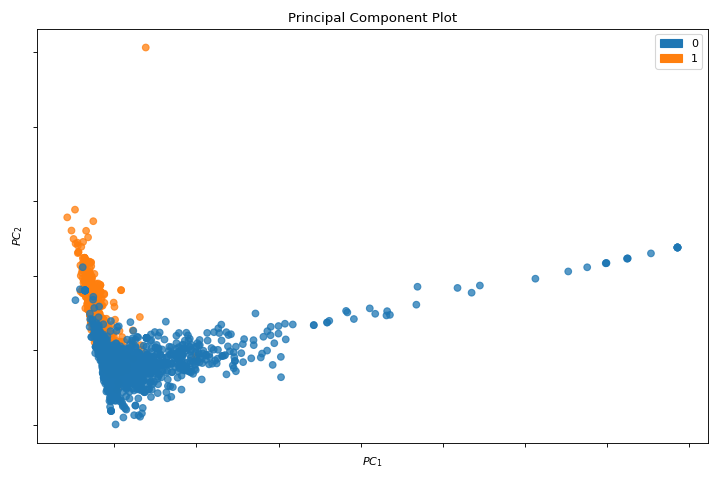
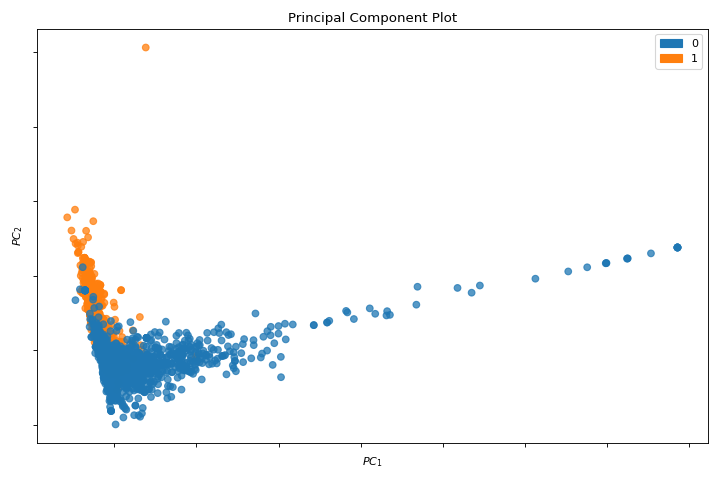
PCA
La pca_decomposition es una proyección de instancias basada en componentes principales. Conoce más en PCA Projection.
from yellowbrick.datasets import load_spam
from yellowbrick.features import pca_decomposition
X, y = load_spam()
visualizer = pca_decomposition(X, y)
(Source code, png, pdf)
{kind=link}
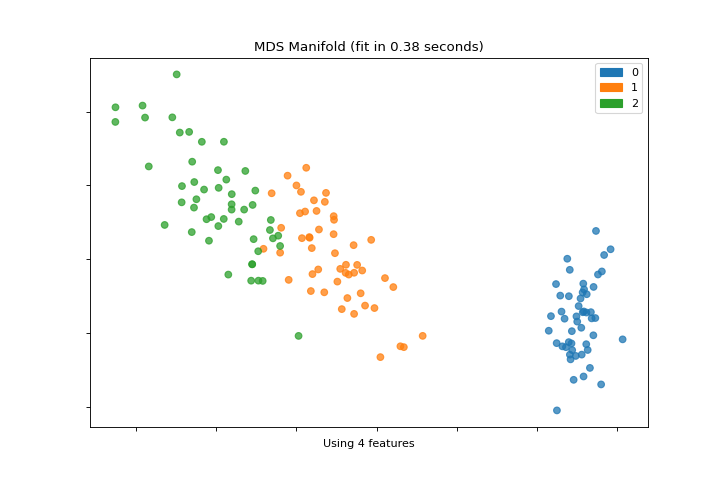
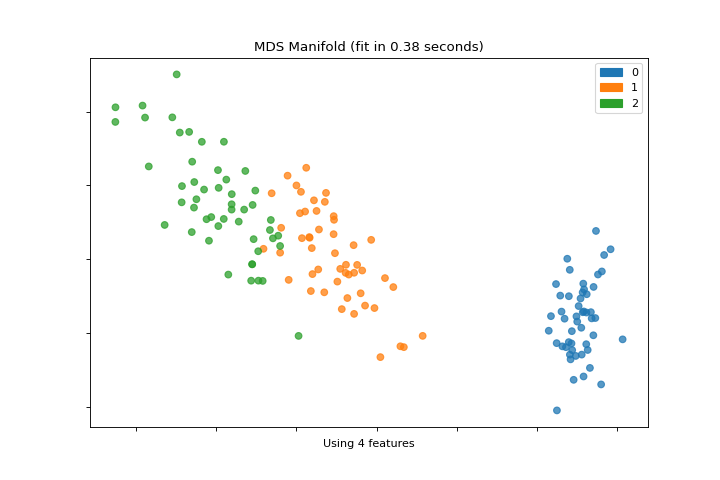
Múltiple
La gráfica manifold_embedding es una visualización de alta dimensión con aprendizaje múltiple, que puede mostrar relaciones no lineales en las características. Conoce más en Manifold Visualization.
from sklearn.datasets import load_iris
from yellowbrick.features import manifold_embedding
X, y = load_iris(return_X_y=True)
visualizer = manifold_embedding(X, y)
(Source code, png, pdf)
{kind=link}
Clasificación
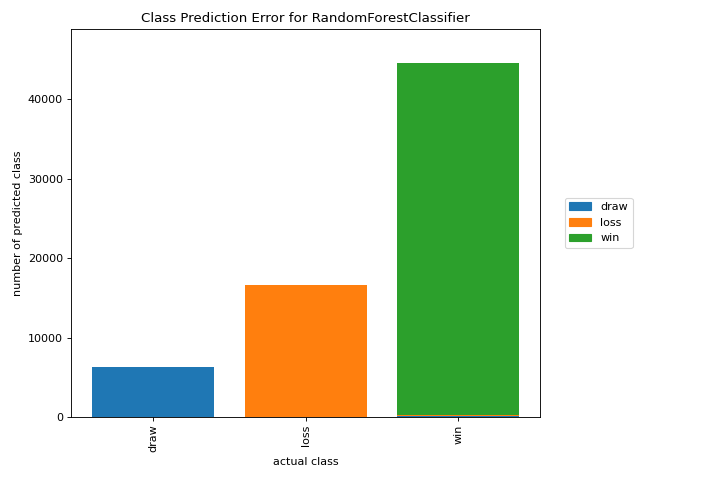
Error de predicción de clase
El gráfico class_prediction_error ilustra el error y la ayuda en una clasificación como un gráfico de barras. Conoce más en Class Prediction Error.
from yellowbrick.datasets import load_game
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import class_prediction_error
X, y = load_game()
X = OneHotEncoder().fit_transform(X)
visualizer = class_prediction_error(
RandomForestClassifier(n_estimators=10), X, y
)
(Source code, png, pdf)
{kind=link}
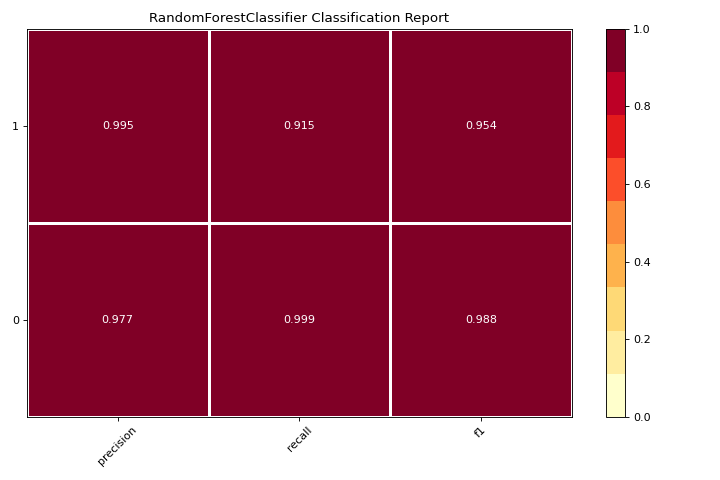
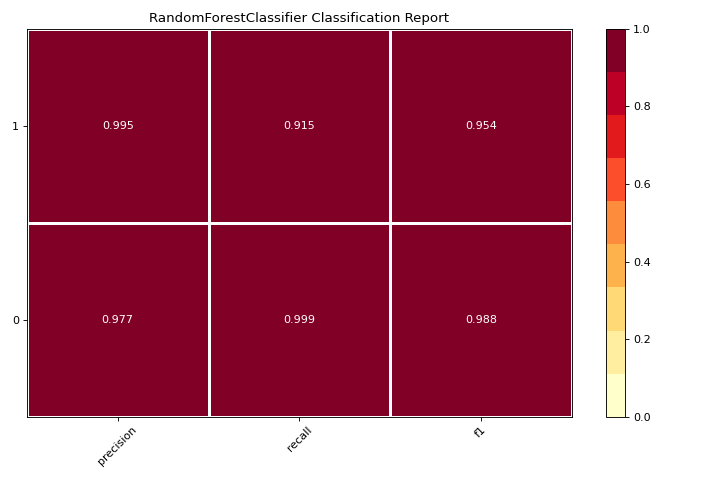
Informe de clasificación
El classification_report es una representación visual de la precisión, recall, y la puntuación F1. Conoce más en Classification Report.
from yellowbrick.datasets import load_credit
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import classification_report
X, y = load_credit()
visualizer = classification_report(
RandomForestClassifier(n_estimators=10), X, y
)
(Source code, png, pdf)
{kind=link}
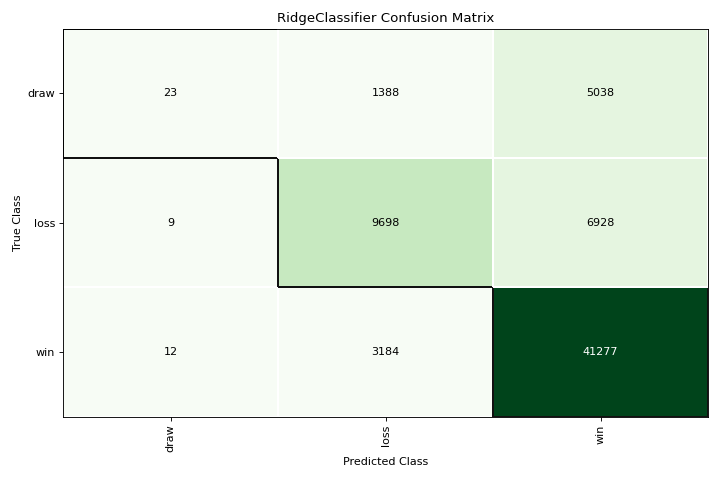
Matriz de confusión
La confusion_matrix es una descripción visual de la toma de decisiones por clase. Conoce más en Confusion Matrix.
from yellowbrick.datasets import load_game
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import RidgeClassifier
from yellowbrick.classifier import confusion_matrix
X, y = load_game()
X = OneHotEncoder().fit_transform(X)
visualizer = confusion_matrix(RidgeClassifier(), X, y, cmap="Greens")
(Source code, png, pdf)
{kind=link}
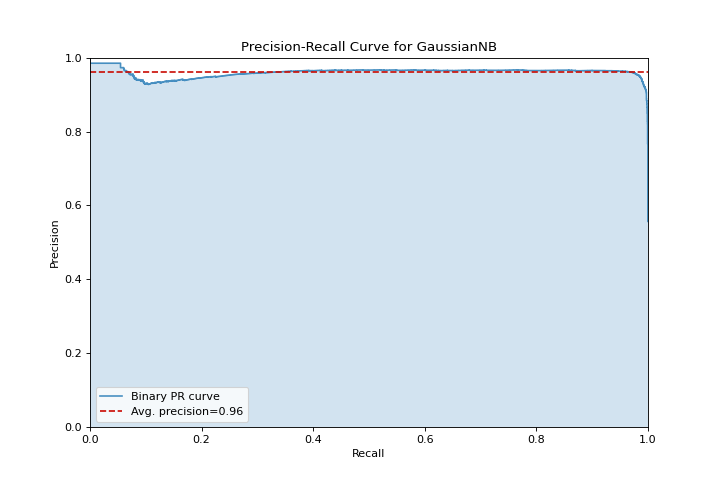
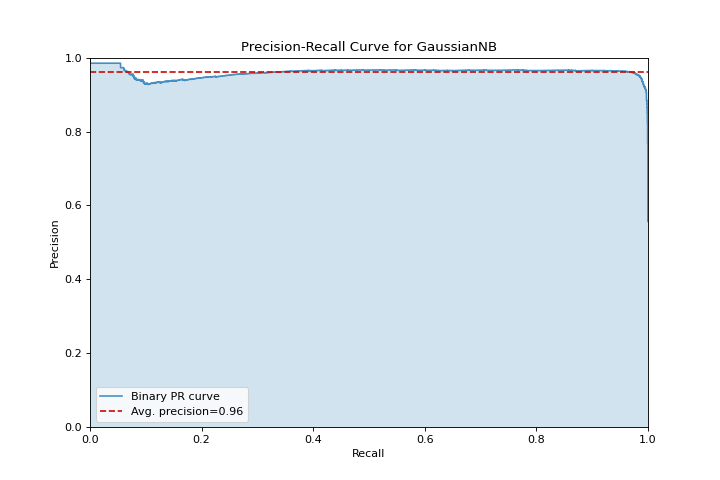
Precisión en el Recall
La precision_recall_curve muestra la compensación entre la precisión y el recall para diferentes umbrales de probabilidad. Conoce más en Precision-Recall Curves.
from sklearn.naive_bayes import GaussianNB
from yellowbrick.datasets import load_occupancy
from yellowbrick.classifier import precision_recall_curve
X, y = load_occupancy()
visualizer = precision_recall_curve(GaussianNB(), X, y)
(Source code, png, pdf)
{kind=link}
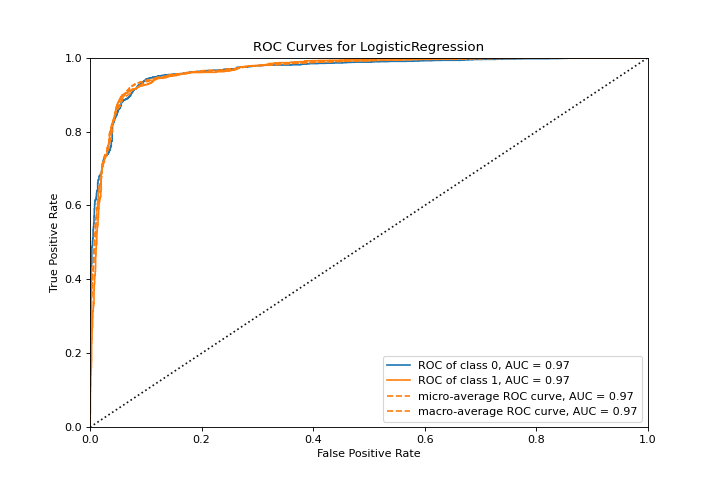
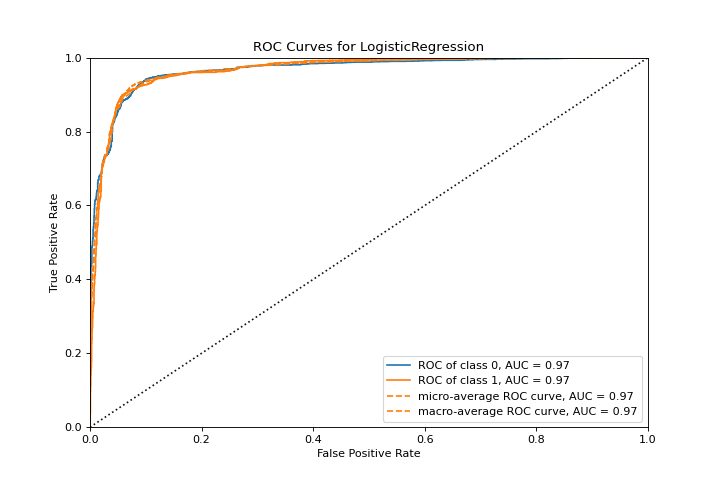
ROCAUC
El gráfico roc_auc muestra las características del operador del receptor y el área debajo de la curva. Conoce más en:doc:api/classifier/rocauc.
from yellowbrick.classifier import roc_auc
from yellowbrick.datasets import load_spam
from sklearn.linear_model import LogisticRegression
X, y = load_spam()
visualizer = roc_auc(LogisticRegression(), X, y)
(Source code, png, pdf)
{kind=link}
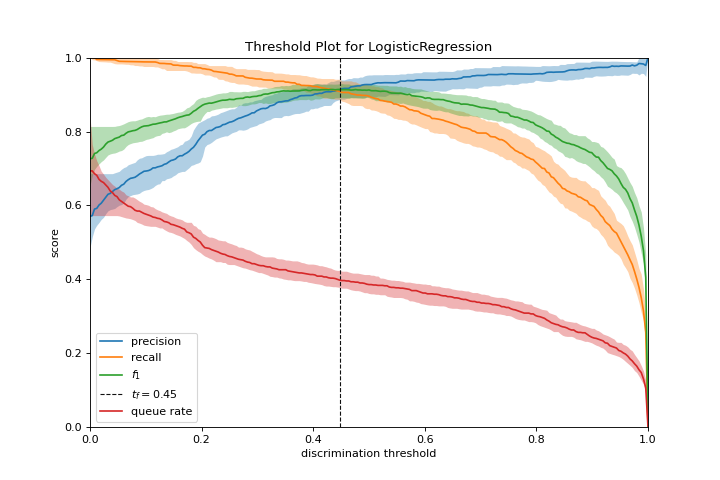
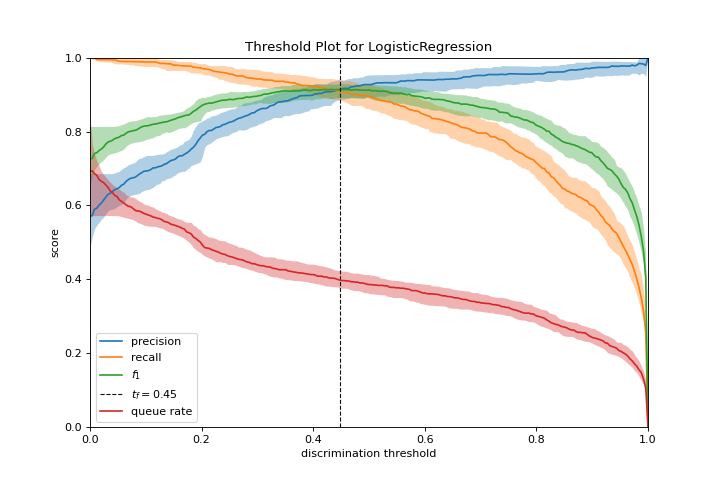
Umbral de discriminación
El gráfico discrimination_threshold puede ayudar a encontrar un umbral que mejor separe las clases binarias. Conoce más en Discrimination Threshold.
from yellowbrick.classifier import discrimination_threshold
from sklearn.linear_model import LogisticRegression
from yellowbrick.datasets import load_spam
X, y = load_spam()
visualizer = discrimination_threshold(
LogisticRegression(multi_class="auto", solver="liblinear"), X, y
)
(Source code, png, pdf)
{kind=link}
Regresión
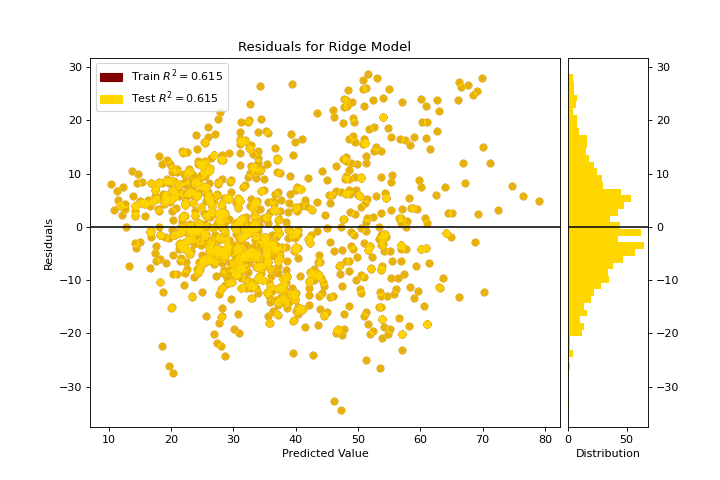
Gráfico de residuos
El residuals_plot muestra la diferencia en los residuos entre los datos de entrenamiento y prueba. Conoce más en Residuals Plot.
from sklearn.linear_model import Ridge
from yellowbrick.datasets import load_concrete
from yellowbrick.regressor import residuals_plot
X, y = load_concrete()
visualizer = residuals_plot(
Ridge(), X, y, train_color="maroon", test_color="gold"
)
(Source code, png, pdf)
{kind=link}
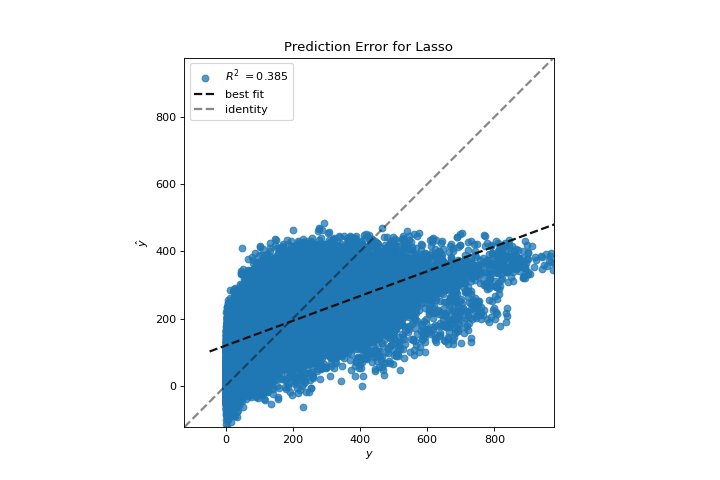
Error de predicción
El prediction_error ayuda a encontrar dónde la regresión está cometiendo la mayoría de los errores. Conoce más en Prediction Error Plot.
from sklearn.linear_model import Lasso
from yellowbrick.datasets import load_bikeshare
from yellowbrick.regressor import prediction_error
X, y = load_bikeshare()
visualizer = prediction_error(Lasso(), X, y)
(Source code, png, pdf)
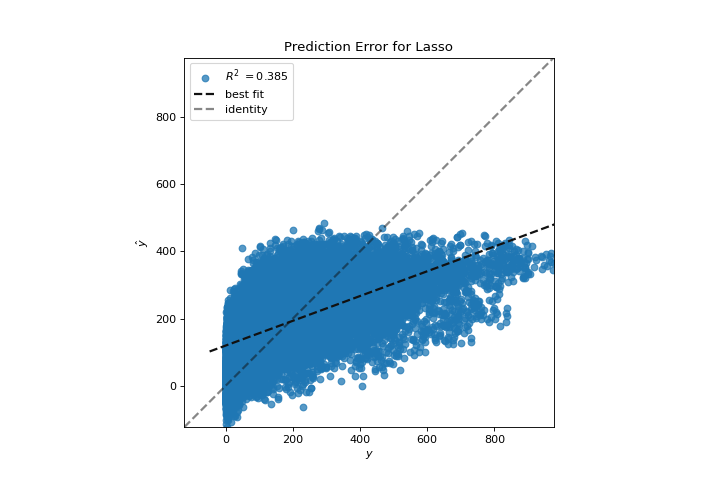{kind=link}
Distancia de Cook
El gráfico cooks_distance muestra la influencia de las instancias en la regresión lineal. Conoce más en Cook’s Distance.
from sklearn.datasets import load_diabetes
from yellowbrick.regressor import cooks_distance
X, y = load_diabetes(return_X_y=True)
visualizer = cooks_distance(X, y)
(Source code, png, pdf)
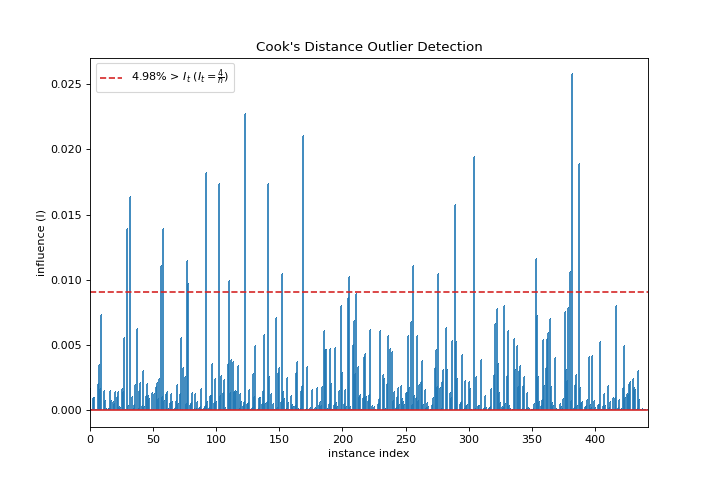{kind=link}
Agrupamiento
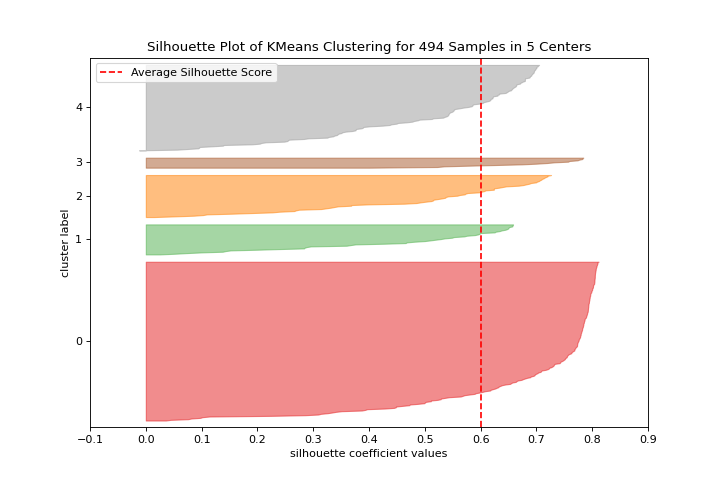
Valores de la silueta
El silhouette_visualizer puede ayudarte a seleccionar k visualizando los valores del coeficiente de la silueta. Conoce más en Silhouette Visualizer.
from sklearn.cluster import KMeans
from yellowbrick.datasets import load_nfl
from yellowbrick.cluster import silhouette_visualizer
X, y = load_nfl()
visualizer = silhouette_visualizer(KMeans(5, random_state=42), X)
(Source code, png, pdf)
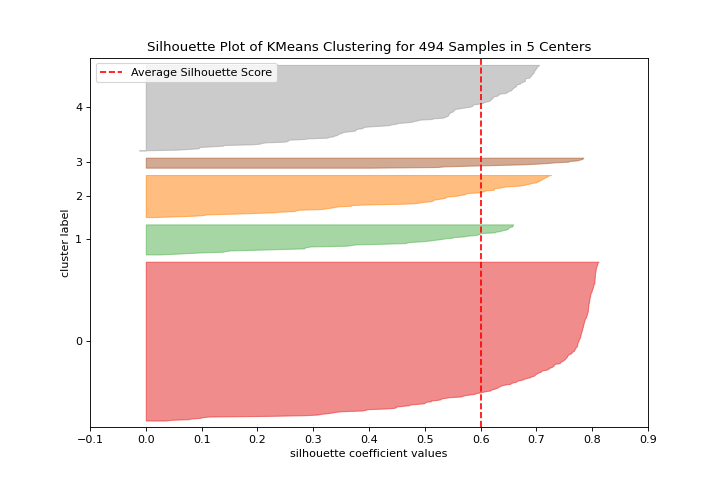{kind=link}
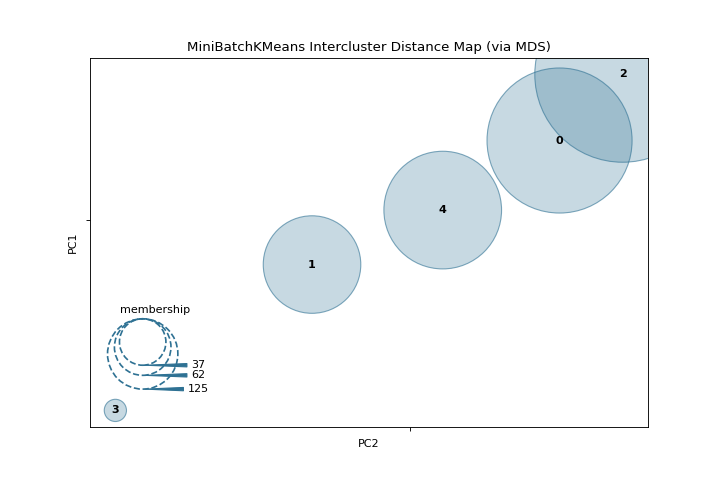
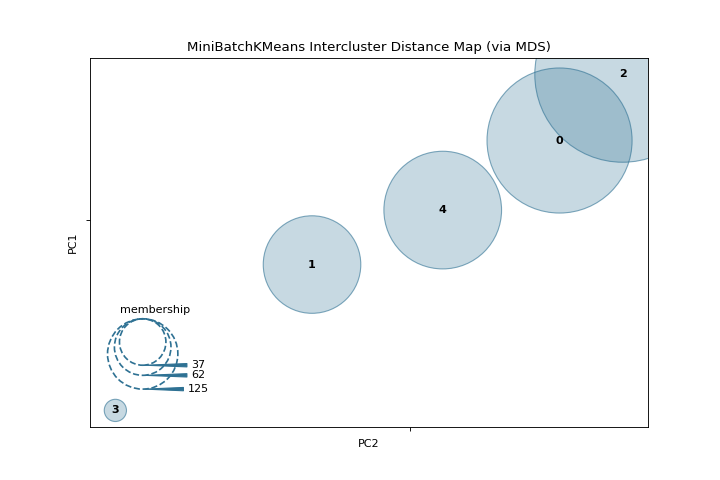
Distancia entre grupos
La intercluster_distance muestra el tamaño y la distancia relativa entre los grupos. Conoce más en Intercluster Distance Maps.
from yellowbrick.datasets import load_nfl
from sklearn.cluster import MiniBatchKMeans
from yellowbrick.cluster import intercluster_distance
X, y = load_nfl()
visualizer = intercluster_distance(MiniBatchKMeans(5, random_state=777), X)
(Source code, png, pdf)
{kind=link}
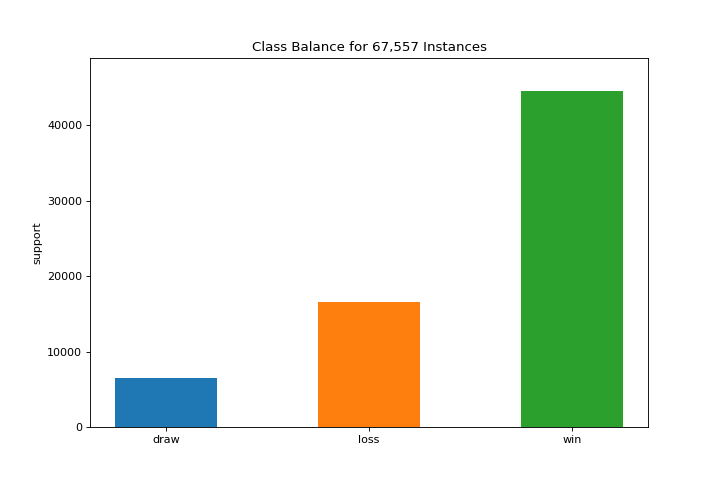
Análisis de objetivos
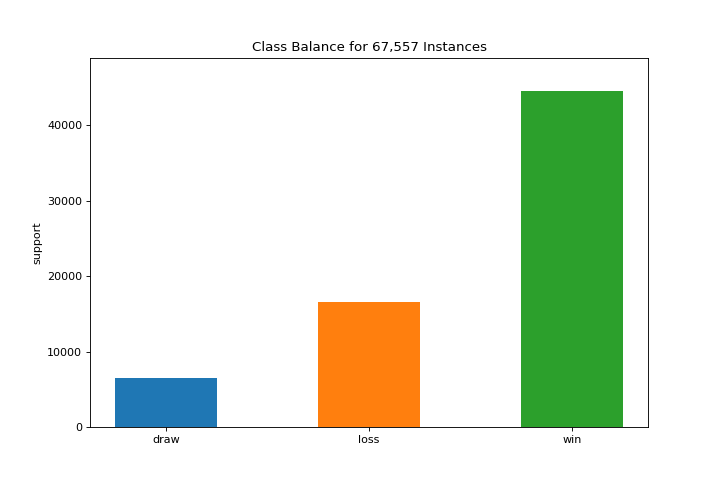
ClassBalance
El gráfico class_balance puede hacer que sea más fácil ver cómo la distribución de clases puede afectar al modelo. Conoce más en Class Balance.
from yellowbrick.datasets import load_game
from yellowbrick.target import class_balance
X, y = load_game()
visualizer = class_balance(y, labels=["draw", "loss", "win"])
(Source code, png, pdf)
{kind=link}