Quick Start
If you’re new to Yellowbrick, this guide will get you started and help you include visualizers in your machine learning workflow. Before we begin, however, there are several notes about development environments that you should consider.
Yellowbrick has two primary dependencies: scikit-learn and matplotlib. If you do not have these Python packages, they will be installed alongside Yellowbrick. Note that Yellowbrick works best with scikit-learn version 0.20 or later and matplotlib version 3.0.1 or later. Both of these packages require some C code to be compiled, which can be difficult on some systems, like Windows. If you’re having trouble, try using a distribution of Python that includes these packages like Anaconda.
Yellowbrick is also commonly used inside of a Jupyter Notebook alongside Pandas data frames. Notebooks make it especially easy to coordinate code and visualizations; however, you can also use Yellowbrick inside of regular Python scripts, either saving figures to disk or showing figures in a GUI window. If you’re having trouble with this, please consult matplotlib’s backends documentation.
Note
Jupyter, Pandas, and other ancillary libraries like the Natural Language Toolkit (NLTK) for text visualizers are not installed with Yellowbrick and must be installed separately.
Installation
Yellowbrick is a Python 3 package and works well with 3.4 or later. The simplest way to install Yellowbrick is from PyPI with pip, Python’s preferred package installer.
$ pip install yellowbrick
Note that Yellowbrick is an active project and routinely publishes new releases with more visualizers and updates. In order to upgrade Yellowbrick to the latest version, use pip as follows.
$ pip install -U yellowbrick
You can also use the -U flag to update scikit-learn, matplotlib, or any other third party utilities that work well with Yellowbrick to their latest versions.
If you’re using Anaconda, you can take advantage of the conda utility to install the Anaconda Yellowbrick package:
conda install -c districtdatalabs yellowbrick
If you’re having trouble with installation, please let us know on GitHub.
Once installed, you should be able to import Yellowbrick without an error, both in Python and inside of Jupyter notebooks. Note that because of matplotlib, Yellowbrick does not work inside of a virtual environment on macOS without jumping through some hoops.
Using Yellowbrick
The Yellowbrick API is specifically designed to play nicely with scikit-learn. The primary interface is therefore a Visualizer – an object that learns from data to produce a visualization. Visualizers are scikit-learn Estimator objects and have a similar interface along with methods for drawing. In order to use visualizers, you simply use the same workflow as with a scikit-learn model, import the visualizer, instantiate it, call the visualizer’s fit() method, then in order to render the visualization, call the visualizer’s show() method.
For example, there are several visualizers that act as transformers, used to perform feature analysis prior to fitting a model. The following example visualizes a high-dimensional data set with parallel coordinates:
from yellowbrick.features import ParallelCoordinates
visualizer = ParallelCoordinates()
visualizer.fit_transform(X, y)
visualizer.show()
As you can see, the workflow is very similar to using a scikit-learn transformer, and visualizers are intended to be integrated along with scikit-learn utilities. Arguments that change how the visualization is drawn can be passed into the visualizer upon instantiation, similarly to how hyperparameters are included with scikit-learn models.
The show() method finalizes the drawing (adding titles, axes labels, etc) and then renders the image on your behalf. If you’re in a Jupyter notebook, the image should just appear in the notebook output. If you’re in a Python script, a GUI window should open with the visualization in interactive form. However, you can also save the image to disk by passing in a file path as follows:
visualizer.show(outpath="pcoords.png")
The extension of the filename will determine how the image is rendered. In addition to the .png extension, .pdf is also commonly used for high-quality publication ready images.
Note
Data input to Yellowbrick is identical to that of scikit-learn. Datasets are
usually described with a variable X (sometimes referred to simply as data) and an optional variable y (usually referred to as the target). The required data X is a table that contains instances (or samples) which are described by features. X is therefore a two-dimensional matrix with a shape of (n, m) where n is the number of instances (rows) and m is the number of features (columns). X can be a Pandas DataFrame, a NumPy array, or even a Python lists of lists.
The optional target data, y, is used to specify the ground truth in supervised machine learning. y is a vector (a one-dimensional array) that must have length n – the same number of elements as rows in X. y can be a Pandas Series, a Numpy array, or a Python list.
Visualizers can also wrap scikit-learn models for evaluation, hyperparameter tuning and algorithm selection. For example, to produce a visual heatmap of a classification report, displaying the precision, recall, F1 score, and support for each class in a classifier, wrap the estimator in a visualizer as follows:
from yellowbrick.classifier import ClassificationReport
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
visualizer = ClassificationReport(model)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
Only two additional lines of code are required to add visual evaluation of the classifier model, the instantiation of a ClassificationReport visualizer that wraps the classification estimator and a call to its show() method. In this way, Visualizers enhance the machine learning workflow without interrupting it.
The class-based API is meant to integrate with scikit-learn directly, however on occasion there are times when you just need a quick visualization. Yellowbrick supports quick functions for taking advantage of this directly. For example, the two visual diagnostics could have been instead implemented as follows:
from sklearn.linear_model import LogisticRegression
from yellowbrick.features import parallel_coordinates
from yellowbrick.classifier import classification_report
# Displays parallel coordinates
g = parallel_coordinates(X, y)
# Displays classification report
g = classification_report(LogisticRegression(), X, y)
These quick functions give you slightly less control over the machine learning workflow, but quickly get you diagnostics on demand and are very useful in exploratory processes.
Walkthrough
Let’s consider a regression analysis as a simple example of the use of visualizers in the machine learning workflow. Using a bike sharing dataset based upon the one uploaded to the UCI Machine Learning Repository, we would like to predict the number of bikes rented in a given hour based on features like the season, weather, or if it’s a holiday.
Note
We have updated the dataset from the UCI ML repository to make it a bit easier to load into Pandas; make sure you download the Yellowbrick version of the dataset using the load_bikeshare method below. Please also note that Pandas is required to follow the supplied code. Pandas can be installed using pip install pandas if you haven’t already installed it.
We can load our data using the yellowbrick.datasets module as follows:
import pandas as pd
from yellowbrick.datasets import load_bikeshare
X, y = load_bikeshare()
print(X.head())
This prints out the first couple lines of our dataset which looks like:
season year month hour holiday weekday workingday weather temp \
0 1 0 1 0 0 6 0 1 0.24
1 1 0 1 1 0 6 0 1 0.22
2 1 0 1 2 0 6 0 1 0.22
3 1 0 1 3 0 6 0 1 0.24
4 1 0 1 4 0 6 0 1 0.24
feelslike humidity windspeed
0 0.2879 0.81 0.0
1 0.2727 0.80 0.0
2 0.2727 0.80 0.0
3 0.2879 0.75 0.0
4 0.2879 0.75 0.0
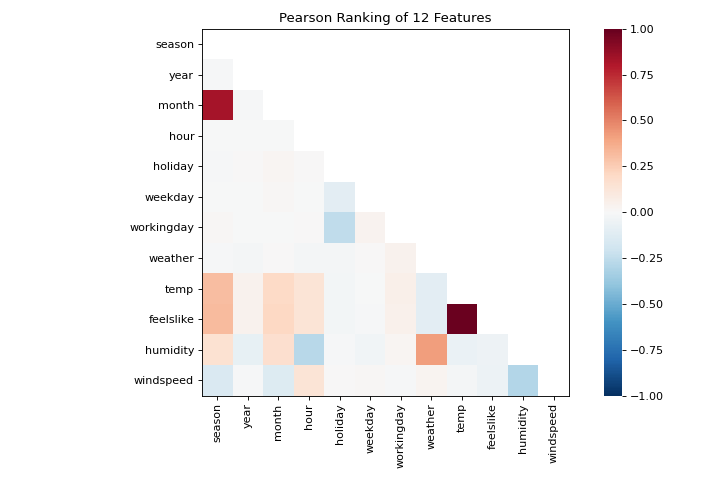
The machine learning workflow is the art of creating model selection triples, a combination of features, algorithm, and hyperparameters that uniquely identifies a model fitted on a specific data set. As part of our feature selection, we want to identify features that have a linear relationship with each other, potentially introducing covariance into our model and breaking OLS (guiding us toward removing features or using regularization). We can use the Rank Features visualizer to compute Pearson correlations between all pairs of features as follows:
from yellowbrick.features import Rank2D
visualizer = Rank2D(algorithm="pearson")
visualizer.fit_transform(X)
visualizer.show()
(Source code, png, pdf)
{kind=link}
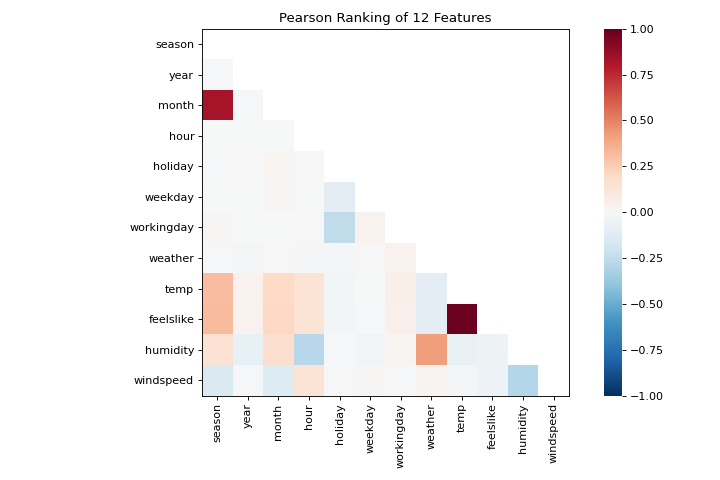
This figure shows us the Pearson correlation between pairs of features such that each cell in the grid represents two features identified in order on the x and y axes and whose color displays the magnitude of the correlation. A Pearson correlation of 1.0 means that there is a strong positive, linear relationship between the pairs of variables and a value of -1.0 indicates a strong negative, linear relationship (a value of zero indicates no relationship). Therefore we are looking for dark red and dark blue boxes to identify further.
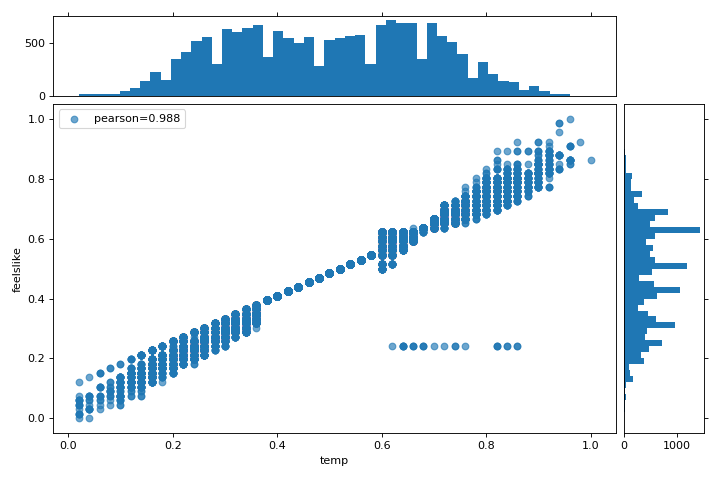
In this chart, we see that the features temp and feelslike have a strong correlation and also that the feature season has a strong correlation with the feature month. This seems to make sense; the apparent temperature we feel outside depends on the actual temperature and other airquality factors, and the season of the year is described by the month! To dive in deeper, we can use the Direct Data Visualization (JointPlotVisualizer) to inspect those relationships.
from yellowbrick.features import JointPlotVisualizer
visualizer = JointPlotVisualizer(columns=['temp', 'feelslike'])
visualizer.fit_transform(X, y)
visualizer.show()
(Source code, png, pdf)
{kind=link}
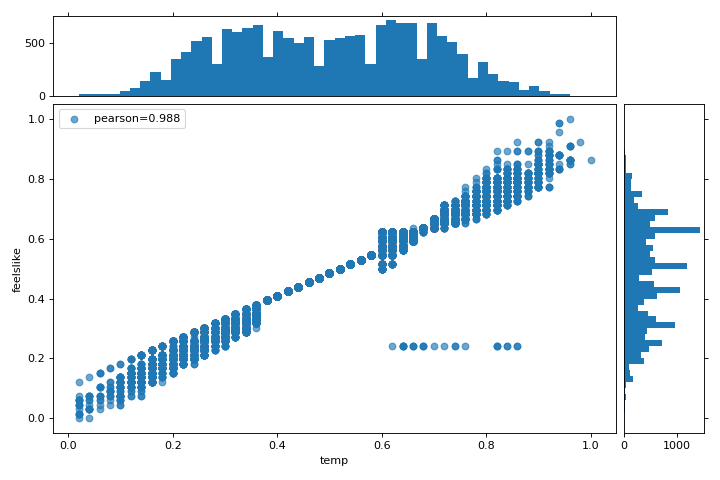
This visualizer plots a scatter diagram of the apparent temperature on the y axis and the actual measured temperature on the x axis and draws a line of best fit using a simple linear regression. Additionally, univariate distributions are shown as histograms above the x axis for temp and next to the y axis for feelslike. The JointPlotVisualizer gives an at-a-glance view of the very strong positive correlation of the features, as well as the range and distribution of each feature. Note that the axes are normalized to the space between zero and one, a common technique in machine learning to reduce the impact of one feature over another.
This plot is very interesting because there appear to be some outliers in the dataset. These instances may need to be manually removed in order to improve the quality of the final model because they may represent data input errors, and potentially train the model on a skewed dataset which would return unreliable model predictions. The first instance of outliers occurs in the temp data where the feelslike value is approximately equal to 0.25 - showing a horizontal line of data, likely created by input error.
We can also see that more extreme temperatures create an exaggerated effect in perceived temperature; the colder it is, the colder people are likely to believe it to be, and the warmer it is, the warmer it is perceived to be, with moderate temperatures generally having little effect on individual perception of comfort. This gives us a clue that feelslike may be a better feature than temp - promising a more stable dataset, with less risk of running into outliers or errors.
We can ultimately confirm the assumption by training our model on either value, and scoring the results. If the temp value is indeed less reliable, we should remove the temp variable in favor of feelslike . In the meantime, we will use the feelslike value due to the absence of outliers and input error.
At this point, we can train our model; let’s fit a linear regression to our model and plot the residuals.
from yellowbrick.regressor import ResidualsPlot
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1
)
visualizer = ResidualsPlot(LinearRegression())
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
(Source code, png, pdf)
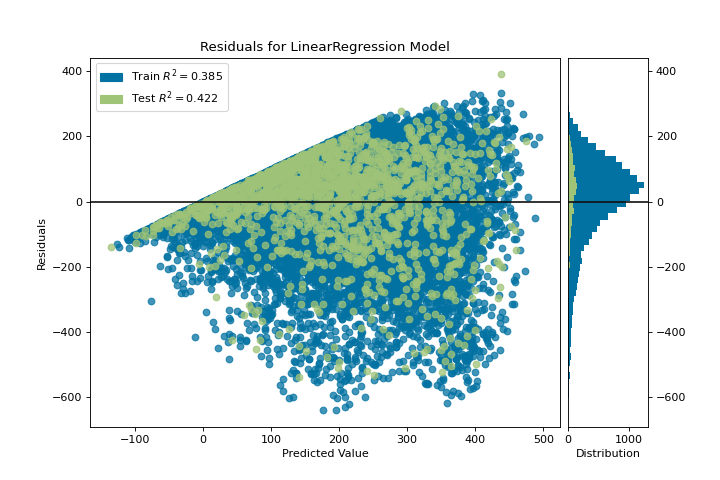{kind=link}
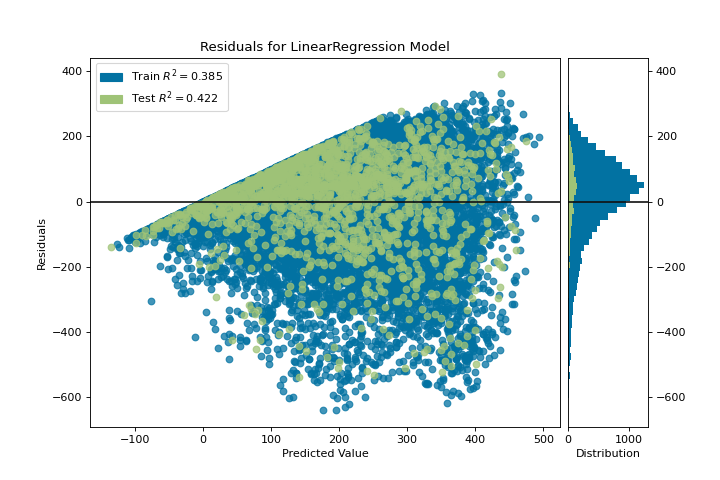
The residuals plot shows the error against the predicted value (the number of riders), and allows us to look for heteroskedasticity in the model; e.g. regions in the target where the error is greatest. The shape of the residuals can strongly inform us where OLS (ordinary least squares) is being most strongly affected by the components of our model (the features). In this case, we can see that the lower predicted number of riders results in lower model error, and conversely that the the higher predicted number of riders results in higher model error. This indicates that our model has more noise in certain regions of the target or that two variables are colinear, meaning that they are injecting error as the noise in their relationship changes.
The residuals plot also shows how the model is injecting error, the bold horizontal line at residuals = 0 is no error, and any point above or below that line indicates the magnitude of error. For example, most of the residuals are negative, and since the score is computed as actual - expected, this means that the expected value is bigger than the actual value most of the time; e.g. that our model is primarily guessing more than the actual number of riders. Moreover, there is a very interesting boundary along the top right of the residuals graph, indicating an interesting effect in model space; possibly that some feature is strongly weighted in the region of that model.
Finally the residuals are colored by training and test set. This helps us identify errors in creating train and test splits. If the test error doesn’t match the train error then our model is either overfit or underfit. Otherwise it could be an error in shuffling the dataset before creating the splits.
Along with generating the residuals plot, we also measured the performance by “scoring” our model on the test data, e.g. the code snippet visualizer.score(X_test, y_test). Because we used a linear regression model, the scoring consists of finding the R-squared value of the data, which is a statistical measure of how close the data are to the fitted regression line. The R-squared value of any model may vary slightly between prediction/test runs, however it should generally be comparable. In our case, the R-squared value for this model was only 0.328, suggesting that linear correlation may not be the most appropriate to use for fitting this data. Let’s see if we can fit a better model using regularization, and explore another visualizer at the same time.
import numpy as np
from sklearn.linear_model import RidgeCV
from yellowbrick.regressor import AlphaSelection
alphas = np.logspace(-10, 1, 200)
visualizer = AlphaSelection(RidgeCV(alphas=alphas))
visualizer.fit(X, y)
visualizer.show()
(Source code, png, pdf)
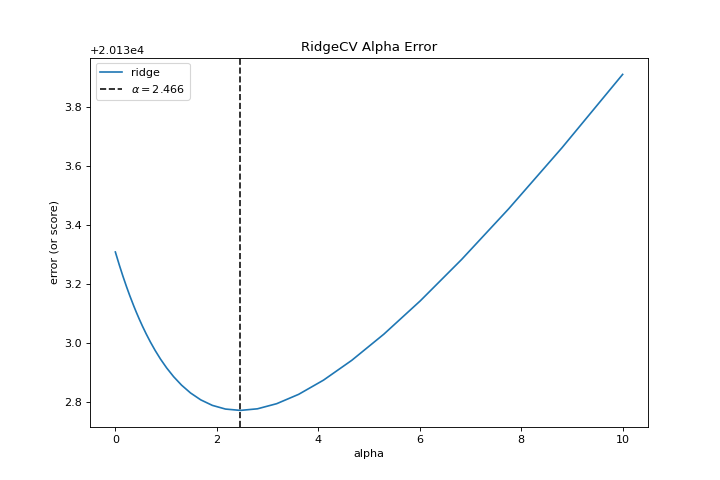{kind=link}
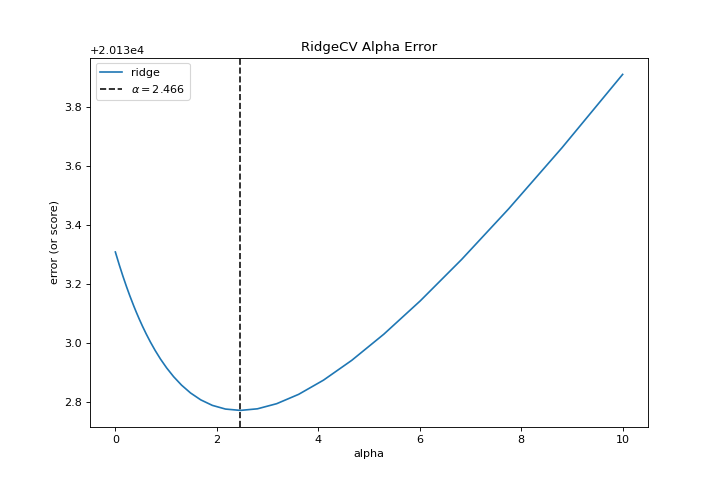
When exploring model families, the primary thing to consider is how the model becomes more complex. As the model increases in complexity, the error due to variance increases because the model is becoming more overfit and cannot generalize to unseen data. However, the simpler the model is the more error there is likely to be due to bias; the model is underfit and therefore misses its target more frequently. The goal therefore of most machine learning is to create a model that is just complex enough, finding a middle ground between bias and variance.
For a linear model, complexity comes from the features themselves and their assigned weight according to the model. Linear models therefore expect the least number of features that achieves an explanatory result. One technique to achieve this is regularization, the introduction of a parameter called alpha that normalizes the weights of the coefficients with each other and penalizes complexity. Alpha and complexity have an inverse relationship, the higher the alpha, the lower the complexity of the model and vice versa.
The question therefore becomes how you choose alpha. One technique is to fit a number of models using cross-validation and selecting the alpha that has the lowest error. The AlphaSelection visualizer allows you to do just that, with a visual representation that shows the behavior of the regularization. As you can see in the figure above, the error decreases as the value of alpha increases up until our chosen value (in this case, 3.181) where the error starts to increase. This allows us to target the bias/variance trade-off and to explore the relationship of regularization methods (for example Ridge vs. Lasso).
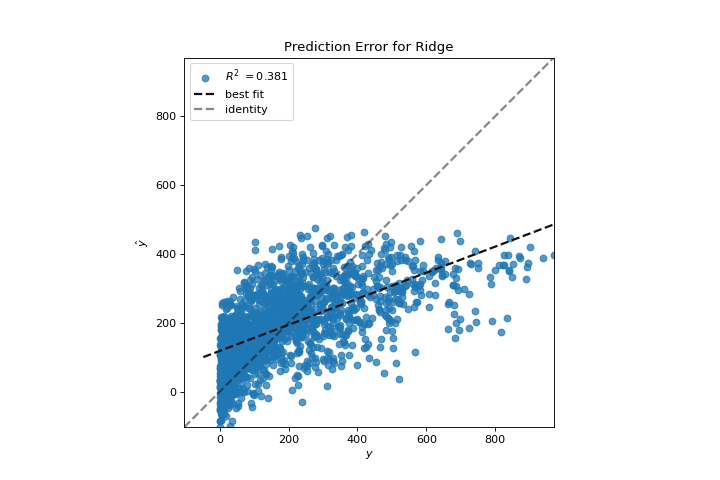
We can now train our final model and visualize it with the PredictionError visualizer:
from sklearn.linear_model import Ridge
from yellowbrick.regressor import PredictionError
visualizer = PredictionError(Ridge(alpha=3.181))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
(Source code, png, pdf)
{kind=link}
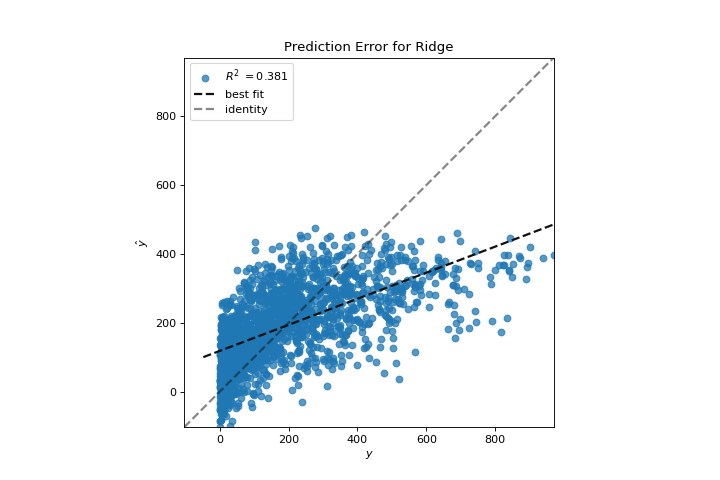
The prediction error visualizer plots the actual (measured) vs. expected (predicted) values against each other. The dotted black line is the 45 degree line that indicates zero error. Like the residuals plot, this allows us to see where error is occurring and in what magnitude.
In this plot, we can see that most of the instance density is less than 200 riders. We may want to try orthogonal matching pursuit or splines to fit a regression that takes into account more regionality. We can also note that that weird topology from the residuals plot seems to be fixed using the Ridge regression, and that there is a bit more balance in our model between large and small values. Potentially the Ridge regularization cured a covariance issue we had between two features. As we move forward in our analysis using other model forms, we can continue to utilize visualizers to quickly compare and see our results.
Hopefully this workflow gives you an idea of how to integrate Visualizers into machine learning with scikit-learn and inspires you to use them in your work and write your own! For additional information on getting started with Yellowbrick, check out the Model Selection Tutorial. After that you can get up to speed on specific visualizers detailed in the Visualizers and API.