PosTag Visualization
Parts of speech (e.g. verbs, nouns, prepositions, adjectives) indicate how a word is functioning within the context of a sentence. In English as in many other languages, a single word can function in multiple ways. Part-of-speech tagging lets us encode information not only about a word’s definition, but also its use in context (for example the words “ship” and “shop” can be either a verb or a noun, depending on the context).
The PosTagVisualizer is intended to support grammar-based feature extraction techniques for machine learning workflows that require natural language processing. The visualizer can either read in a corpus that has already been sentence- and word-segmented, and tagged, or perform this tagging automatically by specifying the parser to use (nltk or spacy). The visualizer creates a bar chart to visualize the relative proportions of different parts-of-speech in a corpus.
Visualizer |
|
Quick Method |
|
Models |
Classification, Regression |
Workflow |
Feature Engineering |
Note
The PosTagVisualizer currently works with both Penn-Treebank (e.g. via NLTK) and Universal Dependencies (e.g. via SpaCy)-tagged corpora. This expects either raw text, or corpora that have already been tagged which take the form of a list of (document) lists of (sentence) lists of (token, tag) tuples, as in the example below.
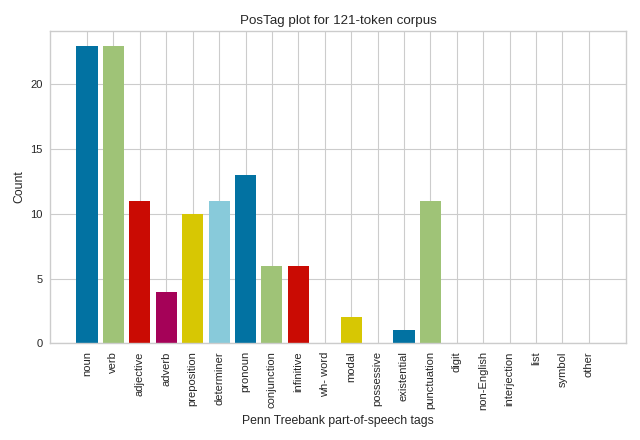
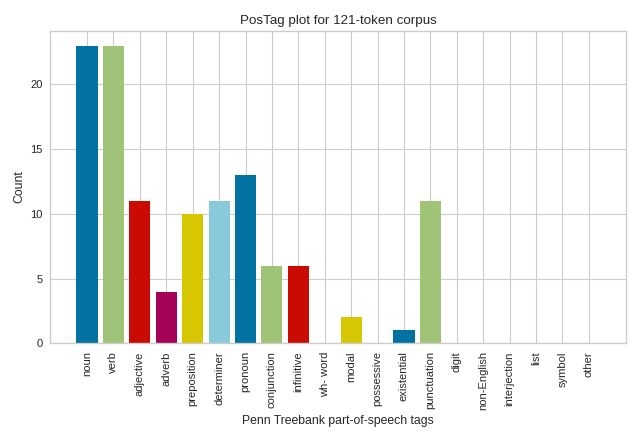
Penn Treebank Tags
from yellowbrick.text import PosTagVisualizer
tagged_stanzas = [
[
[
('Whose', 'JJ'),('woods', 'NNS'),('these', 'DT'),
('are', 'VBP'),('I', 'PRP'),('think', 'VBP'),('I', 'PRP'),
('know', 'VBP'),('.', '.')
],
[
('His', 'PRP$'),('house', 'NN'),('is', 'VBZ'),('in', 'IN'),
('the', 'DT'),('village', 'NN'),('though', 'IN'),(';', ':'),
('He', 'PRP'),('will', 'MD'),('not', 'RB'),('see', 'VB'),
('me', 'PRP'),('stopping', 'VBG'), ('here', 'RB'),('To', 'TO'),
('watch', 'VB'),('his', 'PRP$'),('woods', 'NNS'),('fill', 'VB'),
('up', 'RP'),('with', 'IN'),('snow', 'NNS'),('.', '.')
]
],
[
[
('My', 'PRP$'),('little', 'JJ'),('horse', 'NN'),('must', 'MD'),
('think', 'VB'),('it', 'PRP'),('queer', 'JJR'),('To', 'TO'),
('stop', 'VB'),('without', 'IN'),('a', 'DT'),('farmhouse', 'NN'),
('near', 'IN'),('Between', 'NNP'),('the', 'DT'),('woods', 'NNS'),
('and', 'CC'),('frozen', 'JJ'),('lake', 'VB'),('The', 'DT'),
('darkest', 'JJS'),('evening', 'NN'),('of', 'IN'),('the', 'DT'),
('year', 'NN'),('.', '.')
]
],
[
[
('He', 'PRP'),('gives', 'VBZ'),('his', 'PRP$'),('harness', 'NN'),
('bells', 'VBZ'),('a', 'DT'),('shake', 'NN'),('To', 'TO'),
('ask', 'VB'),('if', 'IN'),('there', 'EX'),('is', 'VBZ'),
('some', 'DT'),('mistake', 'NN'),('.', '.')
],
[
('The', 'DT'),('only', 'JJ'),('other', 'JJ'),('sound', 'NN'),
('’', 'NNP'),('s', 'VBZ'),('the', 'DT'),('sweep', 'NN'),
('Of', 'IN'),('easy', 'JJ'),('wind', 'NN'),('and', 'CC'),
('downy', 'JJ'),('flake', 'NN'),('.', '.')
]
],
[
[
('The', 'DT'),('woods', 'NNS'),('are', 'VBP'),('lovely', 'RB'),
(',', ','),('dark', 'JJ'),('and', 'CC'),('deep', 'JJ'),(',', ','),
('But', 'CC'),('I', 'PRP'),('have', 'VBP'),('promises', 'NNS'),
('to', 'TO'),('keep', 'VB'),(',', ','),('And', 'CC'),('miles', 'NNS'),
('to', 'TO'),('go', 'VB'),('before', 'IN'),('I', 'PRP'),
('sleep', 'VBP'),(',', ','),('And', 'CC'),('miles', 'NNS'),
('to', 'TO'),('go', 'VB'),('before', 'IN'),('I', 'PRP'),
('sleep', 'VBP'),('.', '.')
]
]
]
# Create the visualizer, fit, score, and show it
viz = PosTagVisualizer()
viz.fit(tagged_stanzas)
viz.show()
(Source code, png, pdf)
{kind=link}
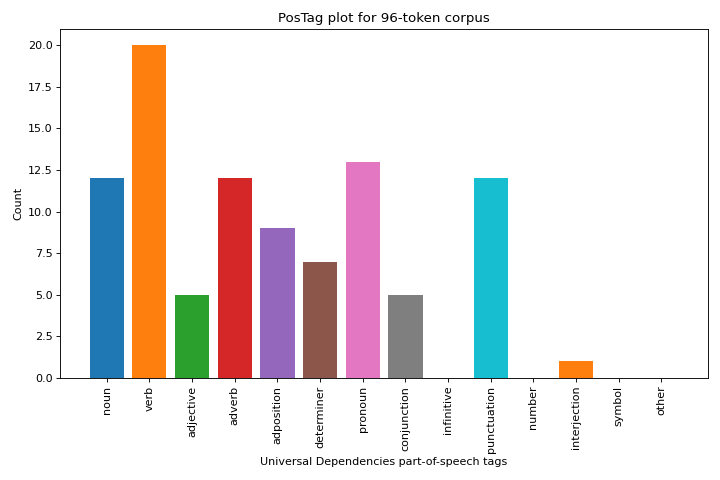
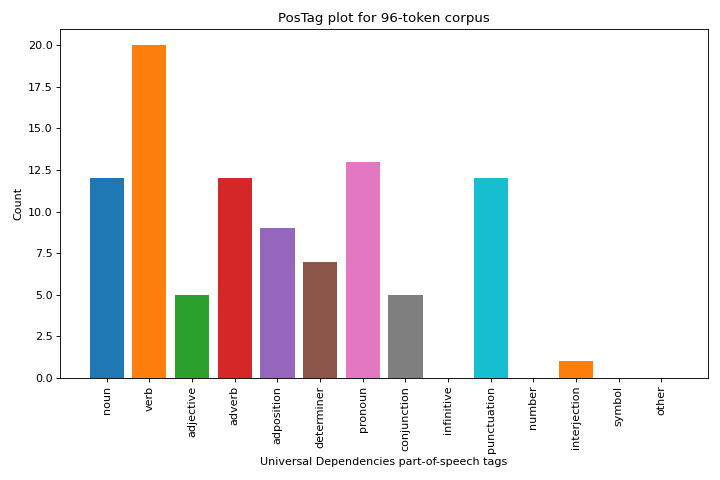
Universal Dependencies Tags
Libraries like SpaCy use tags from the Universal Dependencies (UD) framework. The PosTagVisualizer can also be used with text tagged using this framework by specifying the tagset keyword as “universal” on instantiation.
from yellowbrick.text import PosTagVisualizer
tagged_speech = [
[
[
('In', 'ADP'),('all', 'DET'),('honesty', 'NOUN'),(',', 'PUNCT'),
('I', 'PRON'),('said', 'VERB'),('yes', 'INTJ'),('to', 'ADP'),
('the', 'DET'),('fear', 'NOUN'),('of', 'ADP'),('being', 'VERB'),
('on', 'ADP'),('this', 'DET'),('stage', 'NOUN'),('tonight', 'NOUN'),
('because', 'ADP'),('I', 'PRON'),('wanted', 'VERB'),('to', 'PART'),
('be', 'VERB'),('here', 'ADV'),(',', 'PUNCT'),('to', 'PART'),
('look', 'VERB'),('out', 'PART'),('into', 'ADP'),('this', 'DET'),
('audience', 'NOUN'),(',', 'PUNCT'),('and', 'CCONJ'),
('witness', 'VERB'),('this', 'DET'),('moment', 'NOUN'),('of', 'ADP'),
('change', 'NOUN')
],
[
('and', 'CCONJ'),('I', 'PRON'),("'m", 'VERB'),('not', 'ADV'),
('fooling', 'VERB'),('myself', 'PRON'),('.', 'PUNCT')
],
[
('I', 'PRON'),("'m", 'VERB'),('not', 'ADV'),('fooling', 'VERB'),
('myself', 'PRON'),('.', 'PUNCT')
],
[
('Next', 'ADJ'),('year', 'NOUN'),('could', 'VERB'),('be', 'VERB'),
('different', 'ADJ'),('.', 'PUNCT')
],
[
('It', 'PRON'),('probably', 'ADV'),('will', 'VERB'),('be', 'VERB'),
(',', 'PUNCT'),('but', 'CCONJ'),('right', 'ADV'),('now', 'ADV'),
('this', 'DET'),('moment', 'NOUN'),('is', 'VERB'),('real', 'ADJ'),
('.', 'PUNCT')
],
[
('Trust', 'VERB'),('me', 'PRON'),(',', 'PUNCT'),('it', 'PRON'),
('is', 'VERB'),('real', 'ADJ'),('because', 'ADP'),('I', 'PRON'),
('see', 'VERB'),('you', 'PRON')
],
[
('and', 'CCONJ'), ('I', 'PRON'), ('see', 'VERB'), ('you', 'PRON')
],
[
('—', 'PUNCT')
],
[
('all', 'ADJ'),('these', 'DET'),('faces', 'NOUN'),('of', 'ADP'),
('change', 'NOUN')
],
[
('—', 'PUNCT'),('and', 'CCONJ'),('now', 'ADV'),('so', 'ADV'),
('will', 'VERB'),('everyone', 'NOUN'),('else', 'ADV'), ('.', 'PUNCT')
]
]
]
# Create the visualizer, fit, score, and show it
viz = PosTagVisualizer(tagset="universal")
viz.fit(tagged_speech)
viz.show()
(Source code, png, pdf)
{kind=link}
Quick Method
The same functionality above can be achieved with the associated quick method postag. This method will build the PosTagVisualizer object with the associated arguments, fit it, then (optionally) immediately show the visualization.
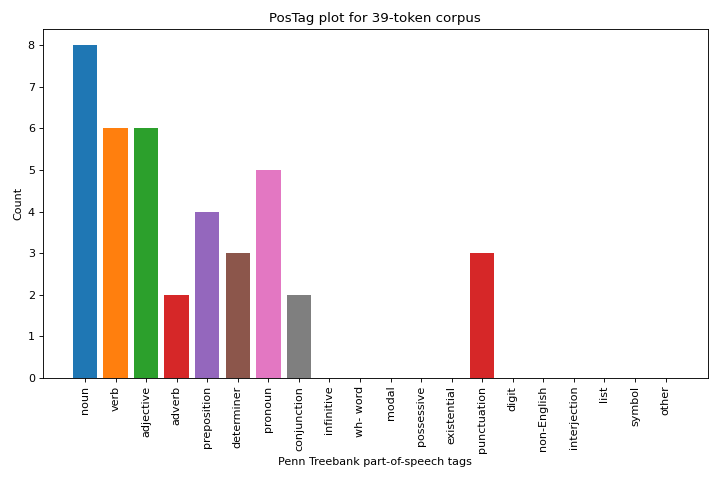
from yellowbrick.text.postag import postag
machado = [
[
[
('Last', 'JJ'), ('night', 'NN'), ('as', 'IN'), ('I', 'PRP'),
('was', 'VBD'), ('sleeping', 'VBG'), (',', ','), ('I', 'PRP'),
('dreamt', 'VBP'), ('—', 'RB'), ('marvelous', 'JJ'), ('error', 'NN'),
('!—', 'IN'), ('that', 'DT'), ('I', 'PRP'), ('had', 'VBD'), ('a', 'DT'),
('beehive', 'NN'), ('here', 'RB'), ('inside', 'IN'), ('my', 'PRP$'),
('heart', 'NN'), ('.', '.')
],
[
('And', 'CC'), ('the', 'DT'), ('golden', 'JJ'), ('bees', 'NNS'),
('were', 'VBD'), ('making', 'VBG'), ('white', 'JJ'), ('combs', 'NNS'),
('and', 'CC'), ('sweet', 'JJ'), ('honey', 'NN'), ('from', 'IN'),
('my', 'PRP$'), ('old', 'JJ'), ('failures', 'NNS'), ('.', '.')
]
]
]
# Create the visualizer, fit, score, and show it
postag(machado)
(Source code, png, pdf)
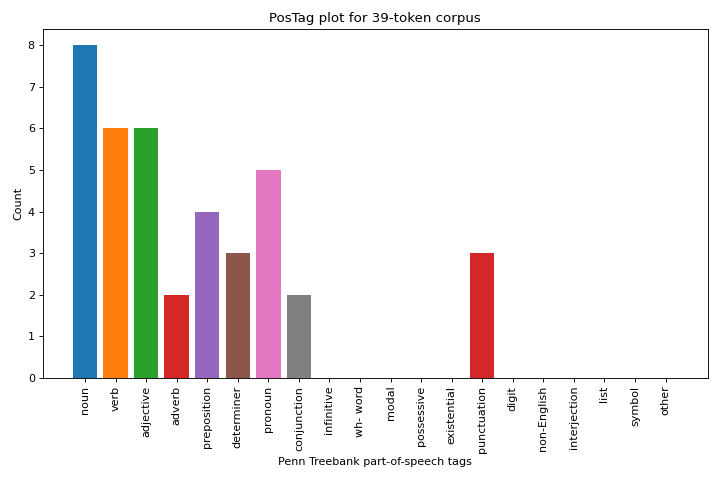{kind=link}
Parsing raw text automatically
The PosTagVisualizer can also be used with untagged text by using the parse keyword on instantiation. The keyword
to parse indicates which natural language processing library to use. To use spacy:
untagged_speech = u'Whose woods these are I think I know'
# Create the visualizer, fit, score, and show it
viz = PosTagVisualizer(parser='spacy')
viz.fit(untagged_speech)
viz.show()
Or, using the nltk parser.
untagged_speech = u'Whose woods these are I think I know'
# Create the visualizer, fit, score, and show it
viz = PosTagVisualizer(parser='nltk')
viz.fit(untagged_speech)
viz.show()
Note
To use either of these parsers, either nltk or spacy must already be installed in your environment.
You can also change the tagger used. For example, using nltk you can select either word (default):
untagged_speech = u'Whose woods these are I think I know'
# Create the visualizer, fit, score, and show it
viz = PosTagVisualizer(parser='nltk_word')
viz.fit(untagged_speech)
viz.show()
Or using wordpunct.
untagged_speech = u'Whose woods these are I think I know'
# Create the visualizer, fit, score, and show it
viz = PosTagVisualizer(parser='nltk_wordpunct')
viz.fit(untagged_speech)
viz.show()
API Reference
Implementation of part-of-speech visualization for text, enabling the user to visualize a single document or small subset of documents.
- class yellowbrick.text.postag.PosTagVisualizer(ax=None, tagset='penn_treebank', colormap=None, colors=None, frequency=False, stack=False, parser=None, **kwargs)[source]
Bases:
TextVisualizerParts of speech (e.g. verbs, nouns, prepositions, adjectives) indicate how a word is functioning within the context of a sentence. In English as in many other languages, a single word can function in multiple ways. Part-of-speech tagging lets us encode information not only about a word’s definition, but also its use in context (for example the words “ship” and “shop” can be either a verb or a noun, depending on the context).
The PosTagVisualizer creates a bar chart to visualize the relative proportions of different parts-of-speech in a corpus.
Note that the PosTagVisualizer requires documents to already be part-of-speech tagged; the visualizer expects the corpus to come in the form of a list of (document) lists of (sentence) lists of (tag, token) tuples.
- Parameters
- axmatplotlib axes
The axes to plot the figure on.
- tagset: string
The tagset that was used to perform part-of-speech tagging. Either “penn_treebank” or “universal”, defaults to “penn_treebank”. Use “universal” if corpus has been tagged using SpaCy.
- colorslist or tuple of strings
Specify the colors for each individual part-of-speech. Will override colormap if both are provided.
- colormapstring or matplotlib cmap
Specify a colormap to color the parts-of-speech.
- frequency: bool {True, False}, default: False
If set to True, part-of-speech tags will be plotted according to frequency, from most to least frequent.
- stackbool {True, False}, defaultFalse
Plot the PosTag frequency chart as a per-class stacked bar chart. Note that fit() requires y for this visualization.
- parserstring or None, default: None
If set to a string, string must be in the form of ‘parser_tagger’ or ‘parser’ to use defaults (for spacy this is ‘en_core_web_sm’, for nltk this is ‘word’). The ‘parser’ argument is one of the accepted parsing libraries. Currently ‘nltk’ and ‘spacy’ are the only accepted libraries. NLTK or SpaCy must be installed into your environment. ‘tagger’ is the tagset to use. For example ‘nltk_wordpunct’ would use the NLTK library with ‘wordpunct’ tagset. Or ‘spacy_en_core_web_sm’ would use SpaCy with the ‘en_core_web_sm’ tagset.
- kwargsdict
Pass any additional keyword arguments to the PosTagVisualizer.
Examples
>>> viz = PosTagVisualizer() >>> viz.fit(X) >>> viz.show()
- Attributes
- pos_tag_counts_: dict
Mapping of part-of-speech tags to counts.
- draw(**kwargs)[source]
Called from the fit method, this method creates the canvas and draws the part-of-speech tag mapping as a bar chart.
- Parameters
- kwargs: dict
generic keyword arguments.
- Returns
- axmatplotlib axes
Axes on which the PosTagVisualizer was drawn.
- finalize(**kwargs)[source]
Finalize the plot with ticks, labels, and title
- Parameters
- kwargs: dict
generic keyword arguments.
- fit(X, y=None, **kwargs)[source]
Fits the corpus to the appropriate tag map. Text documents must be tokenized & tagged before passing to fit if the ‘parse’ argument has not been specified at initialization. Otherwise X can be a raw text ready to be parsed.
- Parameters
- Xlist or generator or str (raw text)
Should be provided as a list of documents or a generator that yields a list of documents that contain a list of sentences that contain (token, tag) tuples. If X is a string, the ‘parse’ argument should be specified as ‘nltk’ or ‘spacy’ in order to parse the raw documents.
- yndarray or Series of length n
An optional array of target values that are ignored by the visualizer.
- kwargsdict
Pass generic arguments to the drawing method
- Returns
- selfinstance
Returns the instance of the transformer/visualizer
- parse_nltk(X)[source]
Tag a corpora using NLTK tagging (Penn-Treebank) to produce a generator of tagged documents in the form of a list of (document) lists of (sentence) lists of (token, tag) tuples.
- Parameters
- Xstr (raw text) or list of paragraphs (containing str)
- parse_spacy(X)[source]
Tag a corpora using SpaCy tagging (Universal Dependencies) to produce a generator of tagged documents in the form of a list of (document) lists of (sentence) lists of (token, tag) tuples.
- Parameters
- Xstr (raw text) or list of paragraphs (containing str)
- property parser
- show(outpath=None, **kwargs)[source]
Makes the magic happen and a visualizer appear! You can pass in a path to save the figure to disk with various backends, or you can call it with no arguments to show the figure either in a notebook or in a GUI window that pops up on screen.
- Parameters
- outpath: string, default: None
path or None. Save figure to disk or if None show in window
- clear_figure: boolean, default: False
When True, this flag clears the figure after saving to file or showing on screen. This is useful when making consecutive plots.
- kwargs: dict
generic keyword arguments.
Notes
Developers of visualizers don’t usually override show, as it is primarily called by the user to render the visualization.
- yellowbrick.text.postag.postag(X, y=None, ax=None, tagset='penn_treebank', colormap=None, colors=None, frequency=False, stack=False, parser=None, show=True, **kwargs)[source]
Display a barchart with the counts of different parts of speech in X, which consists of a part-of-speech-tagged corpus, which the visualizer expects to be a list of lists of lists of (token, tag) tuples.
- Parameters
- Xlist or generator
Should be provided as a list of documents or a generator that yields a list of documents that contain a list of sentences that contain (token, tag) tuples.
- yndarray or Series of length n
An optional array of target values that are ignored by the visualizer.
- axmatplotlib axes
The axes to plot the figure on.
- tagset: string
The tagset that was used to perform part-of-speech tagging. Either “penn_treebank” or “universal”, defaults to “penn_treebank”. Use “universal” if corpus has been tagged using SpaCy.
- colorslist or tuple of colors
Specify the colors for each individual part-of-speech.
- colormapstring or matplotlib cmap
Specify a colormap to color the parts-of-speech.
- frequency: bool {True, False}, default: False
If set to True, part-of-speech tags will be plotted according to frequency, from most to least frequent.
- stackbool {True, False}, defaultFalse
Plot the PosTag frequency chart as a per-class stacked bar chart. Note that fit() requires y for this visualization.
- parserstring or None, default: None
If set to a string, string must be in the form of ‘parser_tagger’ or ‘parser’ to use defaults (for spacy this is ‘en_core_web_sm’, for nltk this is ‘word’). The ‘parser’ argument is one of the accepted parsing libraries. Currently ‘nltk’ and ‘spacy’ are the only accepted libraries. NLTK or SpaCy must be installed into your environment. ‘tagger’ is the tagset to use. For example ‘nltk_wordpunct’ would use the NLTK library with ‘wordpunct’ tagset. Or ‘spacy_en_core_web_sm’ would use SpaCy with the ‘en_core_web_sm’ tagset.
- show: bool, default: True
If True, calls
show(), which in turn callsplt.show()however you cannot callplt.savefigfrom this signature, norclear_figure. If False, simply callsfinalize()- kwargsdict
Pass any additional keyword arguments to the PosTagVisualizer.
- Returns
- visualizer: PosTagVisualizer
Returns the fitted, finalized visualizer